
Cuando tenemos un servidor con Linux o un servidor NAS (que también tiene un sistema operativo basado en Linux) con mucha información en su interior, tanto el propio sistema operativo como archivos y carpetas personales o de nuestro trabajo, es fundamental controlar que los discos duros y las unidades SSD tienen una buena salud y no se van a romper próximamente sin previo aviso. Por este motivo, es muy importante monitorizar de forma contínua el disco duro o SSD de nuestro servidor, para evitar tener pérdida de datos debido a que se rompa. Hoy en RedesZone os vamos a enseñar todo lo que debes controlar en tu servidor con Linux para verificar la salud de tus discos.
La importancia de la salud del disco duro y SSD
Analizar la salud del disco duro de un servidor y un NAS es algo muy importante para garantizar la integridad y disponibilidad de los datos almacenados. Los discos duros son componentes críticos en cualquier sistema de almacenamiento, y su fallo puede provocar la pérdida irreversible de datos, tiempo de inactividad del sistema y costes elevados para recuperar la información perdida. Por lo tanto, llevar a cabo un análisis regular de la salud del disco duro es esencial para prevenir problemas y mantener la estabilidad del sistema.
La importancia de analizar la salud del disco duro está en varios aspectos clave del mismo. En primer lugar, permite detectar y prevenir fallos potenciales antes de que ocurran. Los discos duros pueden experimentar una variedad de problemas con el tiempo, como sectores defectuosos, errores de lectura/escritura, fallas mecánicas y desgaste general. Al monitorear de cerca la salud del disco duro, es posible identificar señales de advertencia y tomar medidas preventivas, como la sustitución del disco antes de que falle por completo.
Además, analizar la salud del disco duro ayuda a garantizar la disponibilidad continua de los datos. Los servidores y NAS suelen utilizarse para almacenar información crítica y sensible que es fundamental para las operaciones diarias. Un fallo repentino del disco duro puede provocar la pérdida de acceso a estos datos, lo que puede tener graves consecuencias para la empresa, incluyendo la interrupción de las operaciones, la pérdida de ingresos y daños a la reputación, por ejemplo.
Otro aspecto importante es la planificación de la capacidad y el rendimiento del sistema. Al analizar la salud del disco duro, es posible evaluar la capacidad restante, el rendimiento y la velocidad de lectura/escritura del disco. Esto nos da información valiosa para planificar futuras expansiones de almacenamiento, optimizar la distribución de datos y garantizar un rendimiento óptimo del sistema.
Qué es el SMART de los discos
Todos los discos duros y unidades SSD disponen de una tecnología llamada SMART, o también conocida como S.M.A.R.T que significa «Self Monitoring Analysis and Reporting Technology». Esta tecnología incorporada en el firmware de los discos duros y SSD consiste en detectar posibles fallos en el disco duro, con el objetivo de anticiparse a errores físicos en el disco duro o fallos inesperados en las unidades SSD debido a la escritura en la memoria flash interna. El objetivo de SMART es avisar a los usuarios para que puedan realizar una copia de seguridad y reemplazar el disco sin tener ninguna pérdida de datos. Si no hacemos caso al SMART, llegará un momento en el que el disco duro se romperá y tendremos pérdida de datos, por lo que es fundamental hacer caso siempre a los datos SMART de los discos.
Para poder utilizar SMART, es totalmente necesario que la BIOS o UEFI del servidor sea compatible con esta tecnología y que esté activada, además, también es totalmente necesario que los discos lo incorporen. Hoy en día todos los servidores, sistemas operativos y discos utilizan esta tecnología para detectar problemas en el disco duro, podríamos decir que es «universal» y que siempre se utiliza.
Esta tecnología se encarga de monitorizar diferentes parámetros del disco duro, como la velocidad de los platos del disco, sectores defectuosos, errores de calibración, comprobación de redundancia cíclica (los típicos errores CRC), temperatura del disco, velocidad de lectura de datos, tiempo de partida (spin-up), contador de sectores reasignados, velocidad de búsqueda (seek time) y otros parámetros muy avanzados que permiten saber lo importante: si el disco duro va a fallar próximamente.
Internamente SMART dispone de un rango de valores que podemos considerar «normal», y cuando un parámetro se sale de estos valores, entonces es cuando salta la alarma, la BIOS/UEFI lo detectará y avisará al sistema operativo de que hay un fallo en el disco y que puede ser grave. En sistemas operativos Linux tenemos la posibilidad de realizar tests de SMART para comprobar si el funcionamiento del disco es el correcto, además, tenemos la posibilidad de programar estos tests para minimizar el impacto en el rendimiento.
Cómo ver la salud del disco
En la mayoría de distribuciones basadas en Linux tenemos un paquete llamado smartmontools. En algunas ocasiones este paquete se encuentra preinstalado en nuestra distribución, y en otras ocasiones tenemos que instalarlo nosotros mismos. Este paquete dispone de dos programas diferentes:
- smartctl: es el programa por línea de comandos que nos permite verificar los discos duros y unidades SSD bajo demanda, o podemos programar su funcionamiento a través del típico cron en el sistema operativo.
- smartd: es un demonio o proceso que verifica que los discos duros o SSD en un intervalo específico no ha tenido ningún fallo. Es capaz de registrar cualquier tipo de aviso o error de los discos al syslog principal del servidor, también permite enviar estos mismos avisos y errores por email al administrador para que compruebe que todo está correcto.
El paquete smartmontools se encarga de monitorizar los discos duros y unidades SSD, independientemente de si utilizan interfaces SATA, SCSI, SAS o NVME, es compatible con cualquier tipo de interfaz de datos. Por supuesto, este programa es completamente gratuito.
Instalación
La instalación de este programa, si es que no está instalado de manera predeterminada en tu distribución de Linux, es utilizando el gestor de paquetes de tu distribución. Por ejemplo, en sistemas operativos Debian con apt sería de la siguiente forma:
sudo apt install smartmontools
Dependiendo del gestor de paquetes de tu distribución, tendrás que usar un comando u otro, lo importante es que este paquete está disponible para todas las distribuciones basadas en Unix y también en Linux, por lo que también podrías instalarlo en FreeBSD sin problemas.
Utilización de smartctl
Para poder utilizar este programa y comprobar la salud de nuestro disco duro, lo primero que debemos hacer es saber cuántos discos duros tenemos, y cuál es la ruta para examinar esos discos duros o SSD en cuestión. Para poder conocer dónde están los discos, debemos ejecutar el siguiente comando:
df -h
También podríamos hacer uso de fdisk para sacar el listado de discos que tenemos en nuestro servidor:
sudo fdisk -l
Estos comandos nos mostrará un listado de las unidades y también de las particiones. Este programa tenemos que utilizarlo a nivel de disco duro o SSD, no a nivel de partición. Generalmente en sistemas Linux encontraremos los discos en la ruta /dev/sdX.
Una vez que sepamos qué unidad vamos a analizar para comprobar su salud a través de SMART, debemos saber que existen un total de dos pruebas diferentes que podemos realizar:
- Prueba corta: esta prueba es la más utilizada para detectar problemas en el disco. Al realizar esta prueba nos mostrará los errores y avisos más importantes, sin necesidad de analizar todo el disco en detalle. Podemos programar esta prueba corta a través de cron para que sea semanal, de esta forma, una vez cada semana realizará este análisis y nos avisará si ha detectado algún error. Es recomendable hacer esta prueba en un horario donde haya poco o ningún uso, no es recomendable hacerlo en horario de trabajo, mejor de madrugada.
- Prueba larga: esta prueba puede durar bastante tiempo, dependiendo del disco y su capacidad. Al realizar esta prueba tan completa, nos mostrará todos los avisos o errores que encuentre en todo el disco. Podemos programar esta prueba larga con cron para que se haga mensual, es decir, una vez cada mes realizaremos esta prueba para comprobar la salud del disco. Es recomendable hacer esta prueba en un horario donde apenas haya uso del disco, por ejemplo, de madrugada, porque de lo contrario el rendimiento en lectura y escritura así como en latencia de acceso a los datos aumentarán considerablemente.
Una vez que ya sabemos los dos tipos de exámenes que podemos usar, lo primero que debemos saber es si el disco duro o SSD tiene activado SMART:
sudo smartctl -i /dev/sda
En el caso de que el disco soporte SMART pero no esté activado, lo podemos activar ejecutando la siguiente orden:
sudo smartctl -s on /dev/sda
Para ver todos los atributos de SMART del fabricante del disco en cuestión, podemos ejecutar la siguiente orden:
sudo smartctl -a /dev/sda
Para realizar un test corto ejecutamos lo siguiente:
sudo smartctl -t short /dev/sda
Para realizar un test largo ejecutamos lo siguiente:
sudo smartctl -t long /dev/sda
Una vez que hayamos realizado el test corto o largo, podemos ejecutar la siguiente orden para ver todos los resultados:
sudo smartctl -H /dev/sda
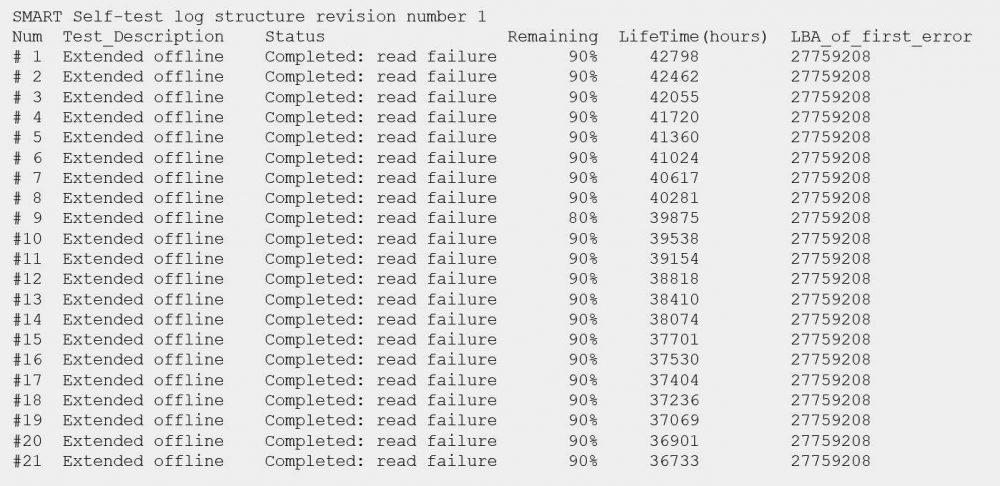
Os recomendamos leer las páginas man de smartctl donde encontraréis todos los comandos que vamos a poder ejecutar para usar las posibilidades de SMART, no obstante, los principales comandos son los que os hemos explicado.
¿En qué valores debo fijarme?
Cuando hacemos un test de SMART, nos va a aparecer una gran cantidad de atributos de nuestro disco duro o SSD. Algunos de estos valores es crítico que nos fijemos muy bien, porque podrían darnos «pistas» de que el disco va a fallar muy pronto:
- Reallocated_Sector_Ct: es el número de sectores que se han reasignados a otras zonas del disco porque ha habido errores de lecturas. Este error es muy típico cuando un disco tiene mucho tiempo y está cerca de terminar su vida útil.
- Spin_Retry_Count: es el número de intentos que han sido necesarios para arrancar el disco, esto indica que hay un grave problema de hardware en el disco, y podría no arrancar la próxima vez.
- Reallocated_Event_Count: número de reasignaciones que se han realizado, ya sea con éxito o sin éxito. Cuanto mayor es el número, peor es la salud del disco duro.
- Current_Pending_Sector: número de sectores que están pendientes de reasignar próximamente.
- Offline_Uncorrectable: número de errores no corregibles al acceder, ya sea en lectura o en escritura a diferentes sectores del disco.
- Multi_Zone_Error_Rate: número total de errores durante la escritura de un sector.
En la siguiente imagen podéis ver el estado de un disco duro WD Red 4TB de nuestro NAS con el sistema operativo XigmaNAS:
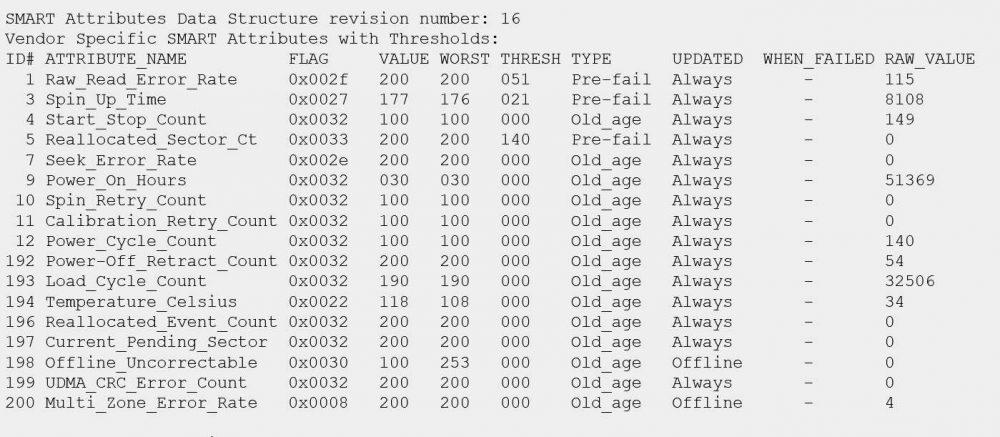
En la anterior captura podéis ver una gran cantidad de información, pero nosotros debemos saber si es un fallo aislado o puede fallar nuestro disco próximamente.
Comprar hardware de calidad
Cuando compramos Discos Duros, es esencial que prestemos atención a algunos criterios y características. Esto hará que nos podamos asegurar de que la unidad adquirida, satisfaga las necesidades y proporcione el rendimiento y durabilidad adecuado. Algunas de estas recomendaciones son:
- Marca y reputación: Lo más recomendable es acudir a marcas más conocidas, las cuales están muy respaldadas por toda la industria. Puede ser Seagate, WD, Toshiba o Samsung, entre otras. Estas cuentan con una larga trayectoria produciendo discos de buena calidad. Y tendremos todos los beneficios que nos aportan como marcas.
- Tipo de disco duro: Debemos decidir el tipo de disco. A pesar de que para los dispositivos NAS está bastante claro, también se pueden comprar en formato SSD, que son mucho más rápidos, pero también más caros. Los HDD, nos ofrecen más capacidad por un precio menor, pero pueden conllevar daños relacionados con sus partes mecánicas.
- Especificaciones y velocidad: Aquí nos vamos a fijar en tres aspectos diferentes. El primero es la velocidad de rotación para los HDD, donde una mayor velocidad suele traducirse en tiempos de acceso y transferencias más rápidas. Por otro lado, la interfaz. Esta es la misma de forma generalizada, ya que los HDD serán por SATAIII mientras que los SSD pueden utilizar M.2 o PCIe. Y por último, el tamaño de la caché. Disponer de más caché nos ayuda a mejorar el rendimiento del componente de forma generalizada.
- Capacidad: Es muy importante conocer cuánto espacio vamos a necesitar. En todo caso, a pesar de que lo tengamos claro, lo mejor es adquirir una unidad que tenga un poco más de espacio del que necesitamos.
- Propósito de uso: En el mercado podemos encontrar discos duros, especialmente pensados para los dispositivos NAS. Por lo cual debemos fijarnos en esto. A pesar de que no pasa nada si compramos discos normales y corrientes, es probable que los dedicados tengan mucho mejor rendimiento si se utilizan para tal efecto.
- Precio: A pesar de que el presupuesto pueda ser limitado, algunas veces el pagar un poco más nos garantiza una mayor calidad y durabilidad. Por lo cual es algo que debe ser estudiado.
Estado de los discos en NAS de QNAP
Sit ienes un servidor NAS de QNAP, Synology o ASUSTOR, también vas a poder ver el estado SMART de tus discos duros y unidades SSD a través del sistema operativo con acceso vía web, no es necesario meternos vía SSH o Telnet y ejecutar ningún comando. En el ejemplo siguiente hemos utilizado un servidor NAS de QNAP, pero el proceso con los otros fabricantes sería muy similar.
Lo primero que tenemos que hacer es irnos a la sección de «Almacenamiento e instantáneas«, una vez aquí, pinchamos en «Almacenamiento /Discos» y veremos algo como esto:
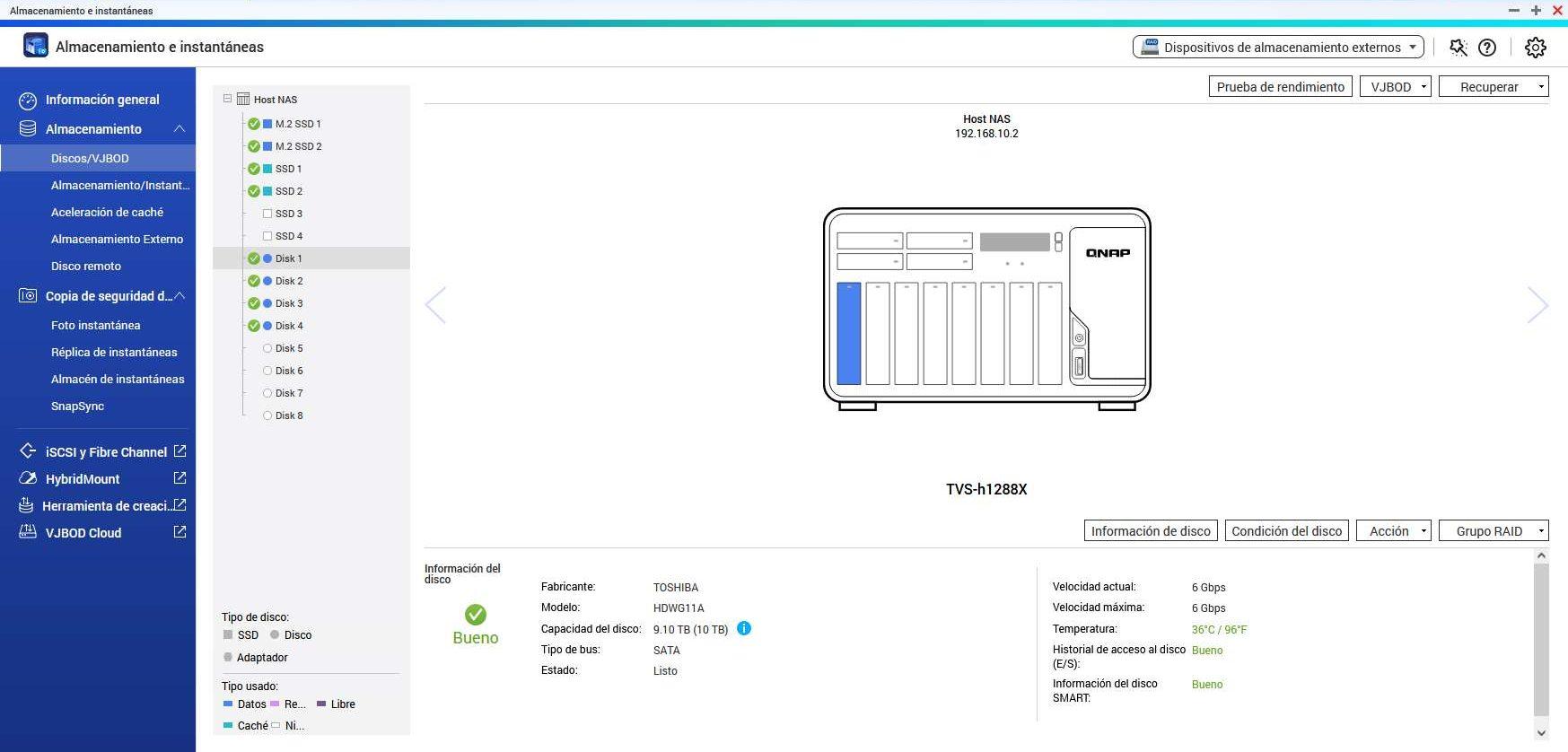
Si pinchamos en «Condición del disco«, tendremos que elegir qué disco de todos queremos mirar. Podemos seleccionar tanto discos duros HDD como también unidades SSD, no importa de qué tipo sean porque también tienen información interna de SMART para ver si hay un error en el disco.
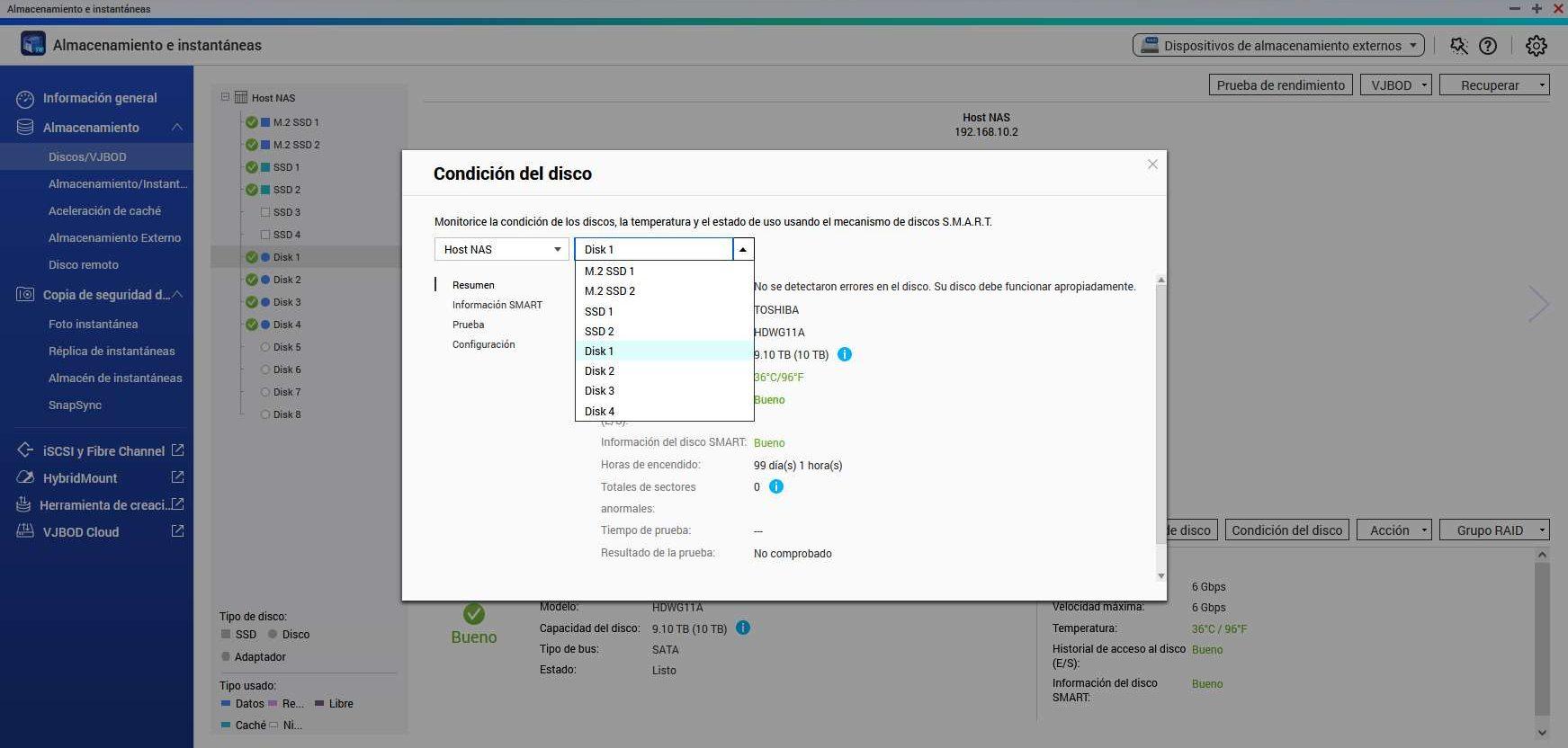
En el menú de «Resumen» podemos ver el estado general del disco, si hay algún tipo de error o aviso grave, también podemos ver la salud general de manera fácil y rápida, sin necesidad de realizar un análisis en detalle de los valores del SMART. Por supuesto, también podemos ver el historial de acceso al disco y si ha existido algún problema.
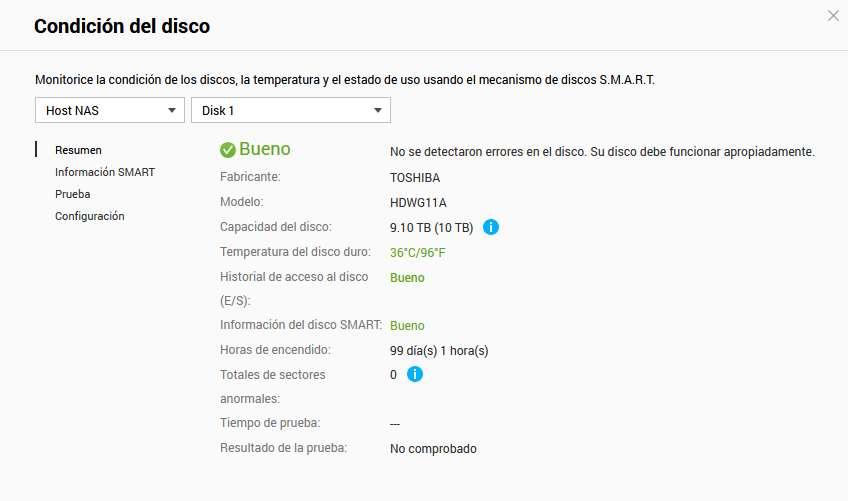
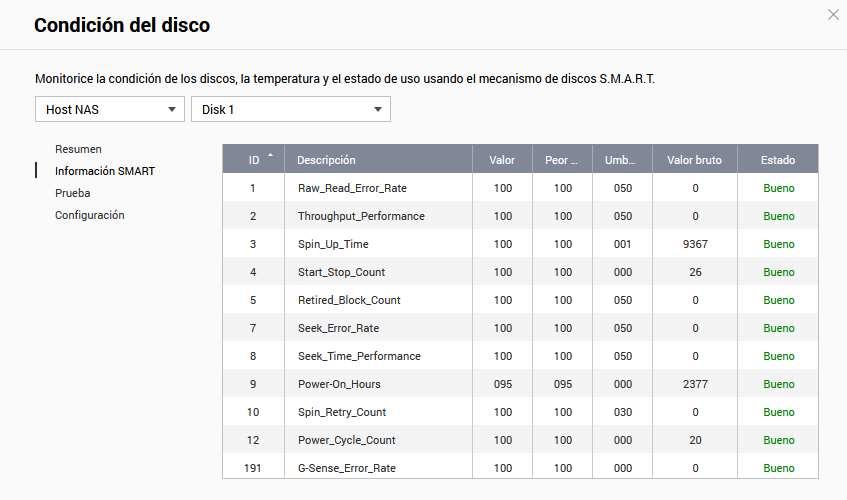
Aunque QNAP nos proporciona información muy fácil de entender, en el caso de que queramos ver todos los valores en bruto, también lo vamos a poder hacer sin problemas. Además, tendremos una columna adicional que nos indica «Estado» y si es bueno o malo.
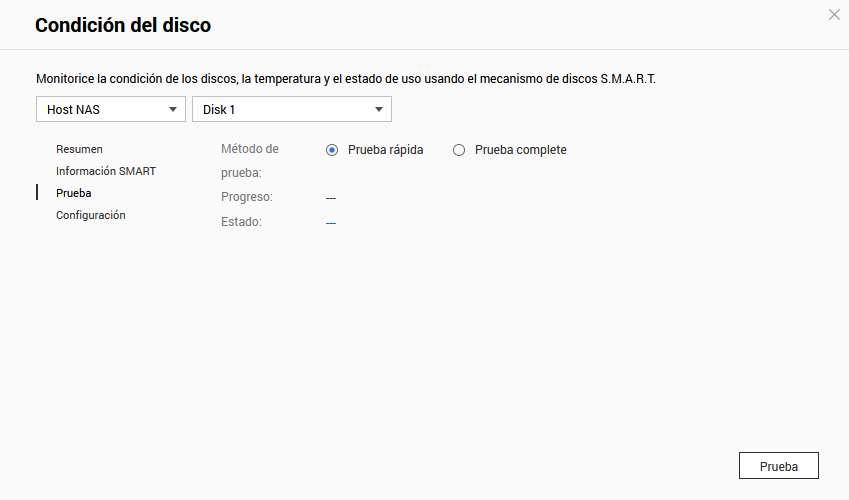
Vamos a poder hacer pruebas rápidas o completas a través de aquí, simplemente tenemos que elegir el método de la prueba y posteriormente pinchar en el botón de «Prueba».
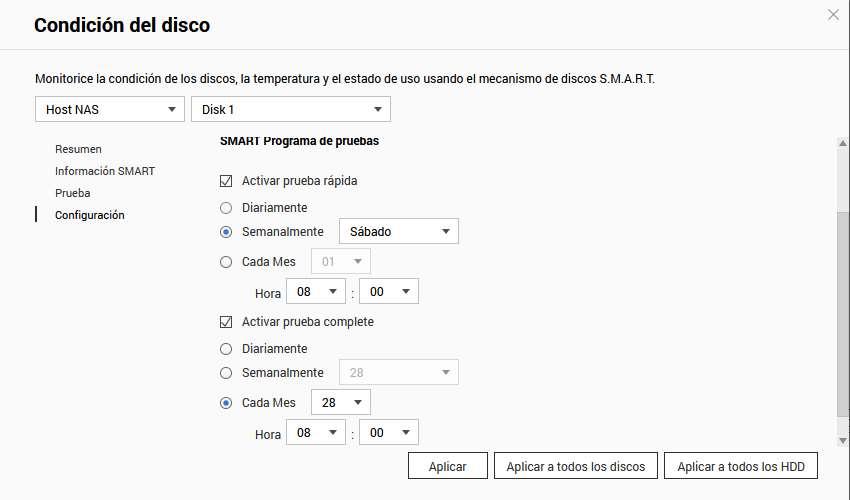
Finalmente, también podemos programar estas pruebas de manera muy fácil, simplemente tenemos que elegir activar prueba rápida o completa, y elegir la frecuencia: diaria, semanal o mensual, además, podemos definir la hora de inicio de esta prueba.
Tal y como podéis ver, comprobar y verificar el estado de salud de los discos duros y SSD en un servidor es algo realmente importante para evitar la pérdida de datos. Cuando ocurre algún tipo de error, es muy importante comprar un nuevo disco y realizar una copia de seguridad para evitar la pérdida de datos. Además, también deberíamos verificar el estado del RAID porque podríamos ocasionar la pérdida de todo el conjunto de almacenamiento, sobre todo si tenemos configurado un RAID 0 o Stripe de ZFS.