
Una función criptográfica hash es un algoritmo matemático que transforma cualquier dato entrante en una serie de caracteres de salida, con una longitud fija o variable, dependiendo del algoritmo hash que estemos utilizando. En los algoritmos de hash con longitud de salida fija, esta longitud será la misma independientemente del tamaño de los datos de entrada. Los algoritmos hash que están específicamente diseñados para proteger contraseñas, suelen ser variables.
No todo el mundo tiene claro de primeras qué es exactamente una función criptográfica hash, también conocido como hash. Por esto mismo, en RedesZone os vamos a explicar todo lo que debes saber sobre los hashes. Desde las propiedades del algoritmo hasta los inicios de SHA2 y SHA3, además de la función común de las KDF.
¿Para qué se utilizan los valores hash?
Los hashes criptográficos se utilizan principalmente para proteger las contraseñas y no guardarlas en texto claro en una base de datos. Si has leído alguna vez algo sobre las funciones hash, lo más probable es que haya sido sobre su principal uso, la protección de contraseñas para evitar almacenarlas en texto claro. Imaginemos que unos cibercriminales son capaces de vulnerar un servicio y robar su base de datos, si no estuvieran hasheadas las contraseñas, sus credenciales se verían expuestos inmediatamente.
Para comprobar que hemos introducido correctamente una contraseña que está guardada en una base de datos (se almacena el hash de la clave), lo que se hace es aplicar el algoritmo hash a la contraseña introducida y compararla con la almacenada, si es igual, la clave es correcta, si es diferente, la clave es incorrecta. Este procedimiento se utiliza en todos los sistemas operativos, webs con autenticación de usuario/clave etc.
Si alguna vez tienes que recuperar o volver a obtener tu contraseña de algún servicio en línea, tendrás que resetearla, porque ni siquiera el propio servicio te podrá proporcionar la contraseña en texto claro, sino que únicamente almacenará al hash de la contraseña. Si en algún servicio has pedido recuperar la contraseña, y te la ofrecen en texto plano, eso significa que las almacenan así, y no es seguro utilizar ese servicio. Aunque las típicas contraseñas 123456 tienen hashes bien conocidos, en cuanto ponemos una clave robusta, no estará en ningún sistema de crackeo de hashes online, y tendremos que crackearlo nosotros mismos con herramientas como Hashcat entre otras.

No todos los usos de los algoritmos hash son para contraseñas, también se utilizan funciones criptográficas hash para detectar malware, se pueden usar para detectar diferentes canciones o películas protegidos por derechos de autor, y crear listas negras. También existen listas públicas de malware, se conocen como firmas de malware, están formadas por valores hash de partes completas o pequeñas partes de malware. Así que, si por un lado, un usuario detecta un archivo sospechoso, puede consultar estas bases de datos de hash públicas, y de esta forma, saber si se trata de un archivo malicioso o si no tiene peligro alguno, a su vez, por el otro lado, también sirven para que los antivirus detecten y bloqueen el malware comparando los hashes de sus propias bases de datos y de las públicas de las que os hablamos.
Otro uso importante de las funciones criptográficas hash, es la de asegurar la integridad de los mensajes. La manera de usarlas para este fin es comprobar los hashes creados antes y después de la transmisión de datos, de esta manera, si los hashes son totalmente idénticos significará que la comunicación ha sido segura y que los datos no han sido alterados, de lo contrario, algo ha fallado de por medio y los datos obtenidos al final de la comunicación no son los mismos que los que se emitieron al inicio.
Rendimiento de los algoritmos hash
Estos algoritmos son una parte muy importante para muchas aplicaciones y sistemas hoy en día. Pero también pueden tener un impacto significativo en estos. Por lo general se utilizan para convertir datos de entrada en representaciones de tamaños fijos, lo cual los hace muy útiles para mucha variedad de tareas. La verificación de contraseñas o detección de intrusos. El rendimiento de estos depende de varios factores, entre ellos el tamaño de los datos de entrada, el algoritmo que utilizamos y la capacidad de procesamiento que tenga el hardware empleado. Cuanto más complejos sean los algoritmos hash, mayor impacto tendrán en el rendimiento.
Como decimos, uno de los factores más importantes es la velocidad a la cual el sistema es capaz de realizar el cálculo del hash. Estos deben ser lo suficientemente rápidos como para no originar un cuello de botella, tanto en las aplicaciones como en los sistemas que se emplean. La gran mayoría de estos algoritmos, están especialmente diseñados para poder ser rápidos y eficientes. Pero, aun así, pueden afectar al rendimiento en muchas situaciones diferentes.
Los datos de entrada también son importantes, ya que cuanto mayor sea el conjunto que se debe procesar, más tiempo tardará en realizar todo el cálculo del hash. Esto en muchas ocasiones puede ser un gran problema, debido a que cada vez las aplicaciones y sistemas deben lidiar con mayores cantidades de datos en tiempo real. Como la tan conocida minería de criptomonedas, donde los hashes se calculan de forma constante. En cuanto a la memoria, también se deben cumplir unos requisitos. Por lo general los algoritmos más complejos pueden requerir cantidades de memoria mayores para poder ser procesados en caché. Lo cual aumenta el coste del hardware de forma considerable, ya que muchas veces es necesario para adaptarse a los requerimientos de un sistema.
Propiedades de buen algoritmo de hash
Una vez queda claro para qué se utilizan los valores hash, lo cierto es que hay que entender desde la base qué es exactamente. Para ello, es necesario conocer cada una de sus propiedades principales. De esta manera, resulta más sencillo entender a fondo qué es una función hash criptográfica:
Por esto mismo, estos son los rasgos clave que todos los buenos hashes comparten, y las resumimos a continuación:
- Determinismo: un algoritmo hash debe ser determinista, lo que significa que siempre le brinda una salida de tamaño idéntico, independientemente del tamaño de la entrada con la que comenzó, esto significa que, si está codificando una sola oración, la salida resultante debe ser del mismo tamaño que la que obtendría al codificar un libro completo.
- Resistencia previa a la imagen: la idea en este punto, es que un algoritmo hash fuerte es uno que es resistente a la imagen previa, lo que significa que no es factible invertir un valor hash para recuperar el mensaje de texto sin formato de entrada original, por lo tanto, el concepto de hash es irreversible, tiene funciones unidireccionales.
- Resistencia a la colisión: una colisión ocurre cuando dos objetos chocan. Bueno, este concepto se traslada a la criptografía con valores hash, si dos muestras únicas de datos de entrada dan como resultado resultados idénticos, se conoce como colisión. Esta es una mala noticia y significa que el algoritmo que está utilizando para codificar los datos no funciona y, por lo tanto, es inseguro, básicamente, la preocupación aquí es que alguien podría crear un archivo malicioso con un valor hash artificial que coincida con un archivo genuino (seguro) y hacerlo pasar por real porque la firma coincidiría, por lo tanto, un algoritmo hash bueno y confiable es aquel que es resistente a estas colisiones.
- Efecto de avalancha: lo que esto significa es que cualquier cambio realizado en una entrada, sin importar cuán pequeño sea, dará como resultado un cambio masivo en la salida, esencialmente, un pequeño cambio (como agregar una coma) se convierte en algo mucho más grande, de ahí el término » efecto avalancha «.
- Velocidad hash: los algoritmos hash deben funcionar a una velocidad razonable, en muchas situaciones, los algoritmos hash deberían calcular los valores hash rápidamente, esto se considera una propiedad ideal de una función hash criptográfica, sin embargo, esta propiedad es un poco más subjetiva. Verás, más rápido no siempre es mejor porque la velocidad debe depender de cómo se utilizará el algoritmo hash, a veces, lo que se desea es un algoritmo hash más rápido, y otras veces es mejor usar uno más lento que tome más tiempo para ejecutarse, el primero es mejor para las conexiones a sitios web y el segundo es mejor para el hash de contraseñas.
- El tamaño: uno de los primeros aspectos que hay que tener en cuenta que cada uno de los hashes criptográficos que se lanzan por cada función tienen la misma longitud, es decir, siempre tienen el mismo tamaño. En caso de ser más largo su código, lo cierto es que será más complejo y de ahí se entiende que su nivel de seguridad sea superior.
- ¿Reversible o no?: otra de las propiedades importantes de las funciones hash es que no son reversibles. Esto quiere decir que aunque se pueda conocer el hash de un documento en particular, no se podrán conocer los datos a partir del hash en sí. Por esto mismo, uno de los usos de estas funciones pasa por guardar contraseñas.
- Siempre da el mismo valor como resultado: es imposible, matemáticamente hablando, que dos archivos distintos puedan tener el mismo hash. Por esto mismo, hay que tener claro que el mismo mensaje siempre dará como resultado el mismo valor hash. De ahí que se usen como huellas digitales informáticas en profesiones como análisis forenses o similar.
Ahora que lo sabemos todo sobre las funciones hash, vamos a ver cuáles son las más utilizadas en la actualidad.
Que más aplicaciones tienen los hash
Las funciones de hash criptográficas se usan para proteger las contraseñas que cada usuario quiera, y así no tenerlas en texto claro dentro de una base de datos. Hasta ahí todo claro, sin embargo, hay otras funciones que se pueden sacar partido de los hashes. Básicamente, otros usos habituales que se pueden aprovechar en cualquier momento:
- Verificar contraseñas: en el momento de que se aplique un hash en una contraseña, el resultado que se ponga se comparará con el listado de valores ya guardados. Por lo que se podrá comprobar si ciertamente está bien o no. Un elemento importante, por ejemplo, en los servidores de las empresas.
- Comprobar archivos y mensajes: otro de los usos comunes de los hashes está en conseguir descubrir si un archivo o mensaje se ha modificado en algún momento. Básicamente, nos puede ayudar a asegurarnos si una tercera persona ha manipulado estos en algún punto. Por lo que es una buena práctica de seguridad que se emplea habitualmente.
- Hashing y por ciberseguridad: si, por ejemplo, una compañía descubre que su seguridad se ha visto comprometida, lo más probable es que los hackers hayan conseguido los hash de estos. Por esto mismo, dentro de la industria de la ciberseguridad se usa el mecanismo salting, es decir, darle un factor aleatorio a cada hash con el objetivo de que cualquier ciberatacante no pueda predecirlo posteriormente, incluso cuando la contraseña en cuestión no sea la más fuerte.
- Generación y hasta la verificación de firmas electrónicas: ya no solo para la generación, también para la comprobación de las firmas, de esta manera se puede autenticar si los documentos o firmas digitales son válidos. Siempre y cuando cumplan una serie de requisitos previos.
SHA2
En sus inicios el algoritmo SHA (Secure Hash Algorithm o Algoritmo de Hash Seguro) fue creado por la NSA y el NIST con el objetivo de generar hashes o códigos únicos en base a una norma. En 1993 nació el primer protocolo SHA, también llamado SHA-0, pero apenas se utilizó y no tuvo demasiada repercusión. Un par de años más tarde, vio la luz una variante mejorada más resistente y segura, el SHA-1, que se ha utilizado durante muchos años para firmar los certificados digitales SSL/TLS de millones de webs. Unos años más tarde se creó SHA-2, que tiene cuatro variantes según el número de bits de salida, son SHA2-224, SHA2-256, SHA2-384 y SHA2-512. Actualmente, por seguridad ya no se utiliza SHA1, sino que es muy recomendable utilizar SHA2 o SHA3 (dentro de la familia SHA).
Funcionamiento del SHA2
Los algoritmos de hash solamente funcionan en una dirección, podemos generar el hash de cualquier contenido, o la huella digital, pero con el hash o la huella digital no hay forma de generar el contenido inicial. La única forma de hacerlo, es mediante diccionario o fuerza bruta, por lo que nos podría llevar miles de años (actualmente) conseguir la información inicial.
Entre las muchas y diferentes formas de crear hashes, el algoritmo SHA2-256 es uno de los más usados gracias a su equilibrio entre seguridad y velocidad, es un algoritmo muy eficiente y tiene una alta resistencia a colisiones, algo muy importante para mantener la seguridad de este algoritmo de hash. Para que un algoritmo hash sea seguro, no se deben conocer colisiones. Por ejemplo, el método de verificar los Bitcoins está basado en SHA2-256.
Características de los diferentes tipos de SHA2
- Tamaño de salida: es el tamaño de caracteres que formarán el hash.
- Tamaño del estado interno: es la suma hash interna, después de cada compresión de un bloque de datos.
- Tamaño del bloque: es el tamaño del bloque que maneja el algoritmo.
- Tamaño máximo del mensaje: es el tamaño máximo del mensaje sobre el que aplicamos el algoritmo.
- Longitud de la palabra: es la longitud en bits de la operación que aplica en cada ronda el algoritmo.
- Interacciones o rondas: es el número de operaciones que realiza el algoritmo para obtener el hash final.
- Operaciones soportadas: son las operaciones que lleva a cabo el algoritmo para obtener el hash final.
SHA-256
Tiene un tamaño de salida de 256 bits, un tamaño de estado interno de 256 bits, un tamaño de bloque de 512 bits, el tamaño máximo del mensaje que puede manejar es de 264 – 1, la longitud de la palabra es de 32 bits, y el número de rondas que se aplican son 64, así como las operaciones que aplica al hash son +, and, or, xor, shr y rot. La longitud del hash siempre es igual, no importa lo grande que sea el contenido que uses para generar el hash: ya sea de sola una letra o una imagen ISO de 4GB de tamaño, el resultado siempre será una sucesión de 40 letras y números.
SHA2-384
Este algoritmo es diferente en cuanto a características, pero su funcionamiento es el mismo. Tiene un tamaño de salida de 384 bits, un tamaño de estado interno de 512 bits, un tamaño de bloque de 1024 bits, el tamaño máximo del mensaje que puede manejar es de 2128 – 1, la longitud de la palabra es de 64 bits, y el número de rondas que se aplican son 80, así como las operaciones que aplica al hash son +, and, or, xor, shr y rot. Este algoritmo es una versión más segura que el SHA2-256, puesto que se aplican más rondas de operaciones y también puede aplicarse sobre una información más extensa. Este algoritmo de hash se suele utilizar para comprobar la integridad de los mensajes y la autenticidad en las redes privadas virtuales. Un aspecto negativo, es que es algo más lento que SHA2-256, pero en determinadas circunstancias puede ser una muy buena opción usar este.
SHA2-512
Como en todos los SHA2, el funcionamiento es el mismo, cambian una sola característica. Tiene un tamaño de salida de 512 bits. El resto de características son iguales que el SHA2-384. 512 bits de tamaño de estado interno, 1024 bits de tamaño de bloque, 2128 – 1 para el tamaño máximo del mensaje, 64 bits de longitud de palabra, y son 80 el número de rondas que se le aplican. Este algoritmo también aplica las mismas operaciones en cada ronda +, and, or, xor, shr y rot.
SHA2-224
No hemos comentado este algoritmo como principal, porque su hermano mayor (SHA2-256) se usa mucho más, ya que la diferencia computacional entre ambos es irrisoria y SHA2-256 está mucho más estandarizado. Lo mencionamos porque, por lo menos hasta el momento, no se han encontrado colisiones para este algoritmo, lo que lo convierte en una opción segura y utilizable.
En la siguiente tabla podremos comprobar mucho mejor las diferencias entre todos los algoritmos en base a sus características.
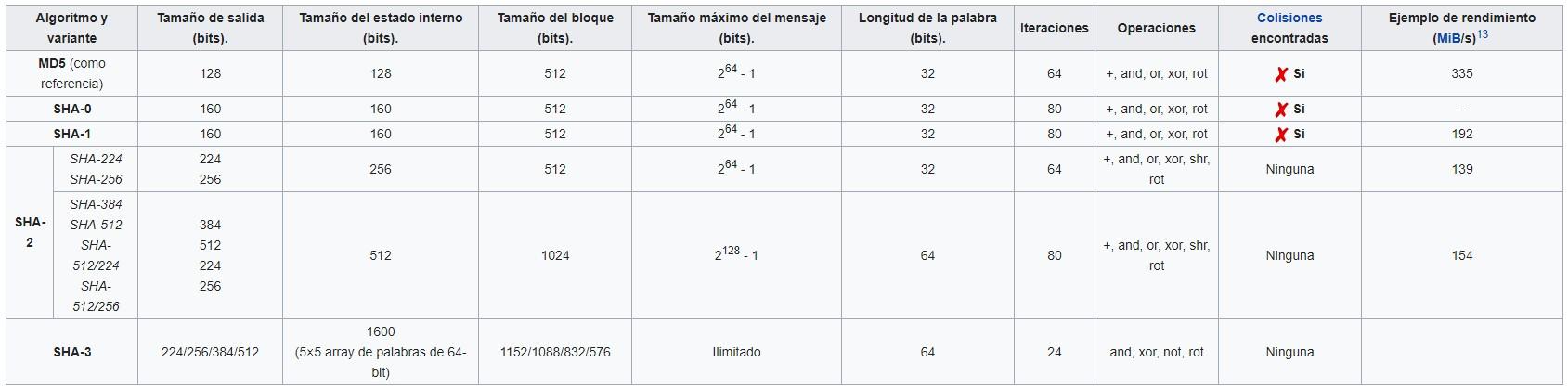
Veréis que en la tabla aparecen previamente los algoritmos hash MD5, SHA-0 y SHA-1, los hemos dejado fuera porque, aunque se han utilizado mucho tiempo atrás, ya se han encontrado colisiones y ya no es seguro utilizarlos, por lo que en la actualidad se usan SHA2, en todas sus variantes, y SHA3.
Para dejar claro el concepto de colisión y que se entienda correctamente os explicamos que, en informática, una colisión de hash es una situación que se produce cuando dos entradas distintas a una función de hash producen la misma salida.
SHA-3
SHA3 es el algoritmo de hash que pertenece a la familia SHA más nuevo, fue publicado por el NISH en 2015, pero aún no se está utilizando ampliamente. Aunque forma parte de la misma familia, su estructura interna es bastante diferente. Este nuevo algoritmo de hash se basa en la «construcción de esponjas». La construcción de esta esponja se basa en una función aleatoria o permutación aleatoria de datos, permite ingresar cualquier cantidad de datos y generar cualquier cantidad de datos, además, la función es pseudoaleatoria con respecto a todas las entradas anteriores. Esto permite a SHA-3 tener una gran flexibilidad, el objetivo está en sustituir a SHA2 en los típicos protocolos TLS o de VPN que utilicen este algoritmo de hash para comprobar la integridad de los datos y la autenticidad de los mismos.
 SHA-3 nació como una alternativa a los SHA2, pero no porque usar SHA-2 sea inseguro, sino porque querían tener un plan B en caso de un ataque exitoso contra SHA2, de esta forma, tanto SHA-2 como SHA-3 convivirán durante bastantes años, de hecho, SHA-3 no se utiliza masivamente como sí ocurre con SHA-2.
SHA-3 nació como una alternativa a los SHA2, pero no porque usar SHA-2 sea inseguro, sino porque querían tener un plan B en caso de un ataque exitoso contra SHA2, de esta forma, tanto SHA-2 como SHA-3 convivirán durante bastantes años, de hecho, SHA-3 no se utiliza masivamente como sí ocurre con SHA-2.
Funcionamiento y características
SHA-3 usa una construcción de «esponja», los datos se «absorben» y se procesan para mostrar una salida con la longitud deseada. En la fase de absorción de los datos, se usa la operación XOR y después se transforman en una función de permutación. SHA-3 permite que tengamos bits adicionales de información, para proteger a la función hash de ataques de extensión, algo que ocurre con MD5, SHA-1 y SHA-2. Otra característica importante, es que es muy flexible, haciendo que se puedan probar ataques criptoanalíticos y usarlo en aplicaciones ligeras. Actualmente SHA2-512 es el doble de rápido que SHA3-512, pero este último se podría implementar a través de hardware, por lo que entonces sí podría ser igual de rápido e incluso más rápido.
Algoritmos Hash KDF
La diferencia entre KDF (Key Derivation Function) y una función de hash para contraseñas, es que la longitud con KDF es diferente, mientras que una función de hash para contraseñas siempre tendrá la misma longitud de salida. Dependiendo de si estamos hasheando claves de cifrado o contraseñas almacenadas en una base de datos, es recomendable utilizar unos algoritmos de hashing u otros. Por ejemplo, en el caso de las contraseñas almacenadas, es recomendable que el algoritmo hash tarde un tiempo de por ejemplo 5 segundos en calcularse, pero que luego sea muy robusto y sea muy costoso el poder crackearlo.
Los desarrolladores menos expertos que no conozcan todas las posibilidades de los algoritmos hash KDF, pensarán que son mejores las funciones de hash criptográficas genéricas unidireccionales de longitud fija y resistentes a colisiones, como son SHA2-256 o SHA2-512, sin pensar dos veces en el posible problema que estas pueden tener. El problema de los hashes de longitud fija es que son rápidas, esto permite a un atacante crackear la contraseña muy rápidamente con un ordenador potente. Los hashes de longitud variable son más lentos, esto es ideal para que los crackeadores de contraseñas tarden más tiempo en obtenerla.
La comunidad criptográfica se unió para introducir funciones de hash diseñadas específicamente para contraseñas, donde se incluye un «coste». Las funciones de derivación de claves también se diseñaron con un «coste». Basándose en las funciones de derivación de claves basadas en contraseñas y las funciones de hash diseñadas específicamente para contraseñas, la comunidad diseñó varios algoritmos para usarlos en la protección de contraseñas.
Los algoritmos más populares para proteger las contraseñas son:
- Argon2 (KDF)
- scrypt (KDF)
- bcrypt
- PBKDF2 (KDF)
La principal diferencia entre un KDF y una función de hash de contraseñas, es que la longitud con los KDF es arbitraria, y en las típicas funciones hash de contraseñas como MD5, SHA-1, SHA2-256, SHA2-512 tienen una salida de longitud fija.
Para el almacenamiento de contraseñas, la amenaza es que la base de datos de claves se filtre a Internet, y que los crackeadores de contraseñas de todo el mundo trabajen en los hashes de la base de datos para recuperar las contraseñas.
Tomando como ejemplo el almacenamiento de contraseñas en una base de datos, cuando iniciamos sesión para acceder a un sitio web, siempre es necesario que el hashing de la clave se haga rápido, para no tener que estar esperando sin poder acceder, pero esto supone un problema, y es que se podría crackear de forma más rápida, sobre todo si usamos la potencia de las GPU junto con Hashcat.
bcrypt, sha256crypt, sha512crypt y PBKDF2
En la siguiente tabla hay una comparación de varios algoritmos de hash ampliamente utilizados, con su correspondiente coste en una tabla. Veréis que está resaltado la fila verde donde un posible factor de trabajo podría significar gastar 0.5 segundos en hash de la contraseña, lo que es una relación bastante buena, y una fila roja donde un posible factor de trabajo podría significar dedicar 5 segundos completos a crear una clave de cifrado basada en contraseña, lo que es malo por la pérdida de eficiencia.
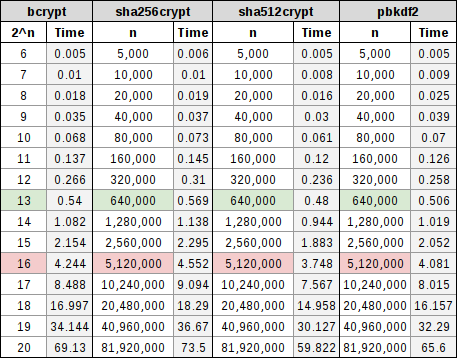
Hay que tener en cuenta que, para bcrypt, esto significa que, para el hash de contraseñas, un factor de 13 proporcionaría un coste de aproximadamente 0,5 segundos para codificar la contraseña, mientras que un factor de 16 me acercaría a un coste de aproximadamente 5 segundos para crear una contraseña basada en llave. Para sha256crypt, sha512crypt y PBKDF2, eso parece ser aproximadamente 640.000 y 5.120.000 iteraciones respectivamente.
scrypt
Cuando pensamos en pasarnos a scrypt es porque las cosas se están poniendo un poco más difíciles. Con bcrypt, sha256crypt, sha512crypt y PBKDF2, nuestro coste es completamente un factor de carga de la CPU, a mayor capacidad de procesamiento, mayor eficiencia del algoritmo. La parte mala es que aún son víctimas de FPGA y ASIC específicos de algoritmos. Para combatir esto, se puede incluir un coste de memoria. Con scrypt tendremos un coste tanto de CPU como de RAM.
En la siguiente tabla se puede ver una comparativa con diferentes valores de coste.
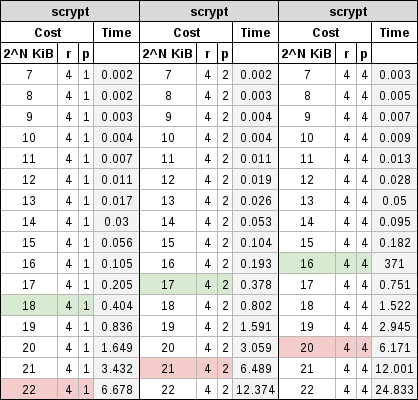
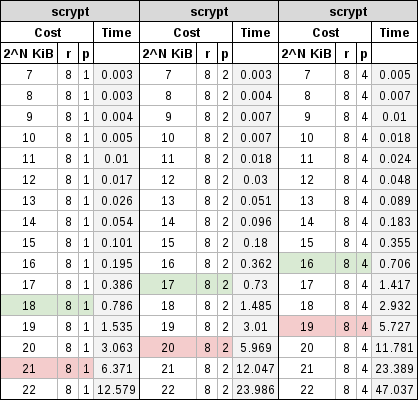
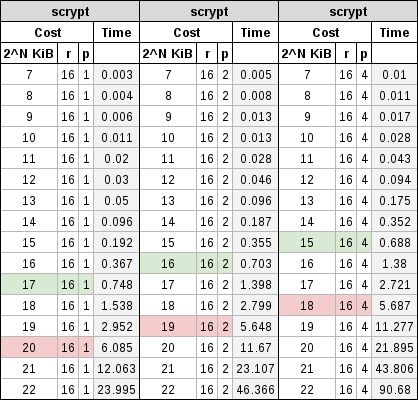
Estas pruebas se han realizado con una CPU de cuatro núcleos de un solo procesador, se ha tratado de limitar el coste «p» a 1, 2 y 4. Se ha limitado también el uso de la RAM y así no tener que interrumpir el resto de acciones en curso que se estaban llevando a cabo. Por lo que se ha limitado el coste «r» a 4, 8 y 16 multiplicado por 128 bytes (512 bytes, 1024 bytes y 2048 bytes).
Argon2
Argon2 tiene dos versiones distintas: Argon2d y Argon2i; el primero depende de los datos (d) y el segundo es independiente de los datos (i). Se supone que el primero es resistente al crackeo de la GPU, mientras que el segundo es resistente a los ataques de canal lateral. En otras palabras, Argon2d sería adecuado para el hash de contraseñas, mientras que Argon2i sería adecuado para la derivación de claves de cifrado.
Argon2 tiene un coste de CPU y un coste de RAM, ambos se manejan por separado. El coste de la CPU se maneja a través de iteraciones estándar, como con bcrypt o PBKDF2, y el coste de la RAM se maneja aumentando específicamente la memoria. Cuando se comenzaron a hacer pruebas con este algoritmo, se vio que simplemente con manipular las iteraciones se acababa pareciendo mucho a bcrypt, pero a su vez, se podía afectar el tiempo total que tomaba calcular el hash simplemente manipulando la memoria. Al combinar los dos, se descubrió que las iteraciones afectaban al coste de CPU más que al de la RAM, pero ambos tenían una participación significativa en el tiempo de cálculo, como se puede ver en las tablas a continuación. Al igual que con scrypt, también tiene un coste de paralelización, que define la cantidad de subprocesos que desea que trabajen en el problema:
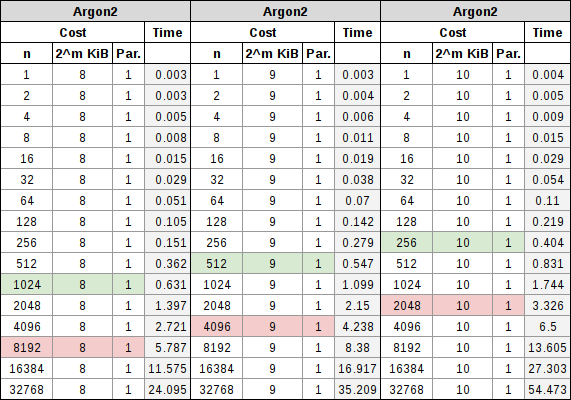
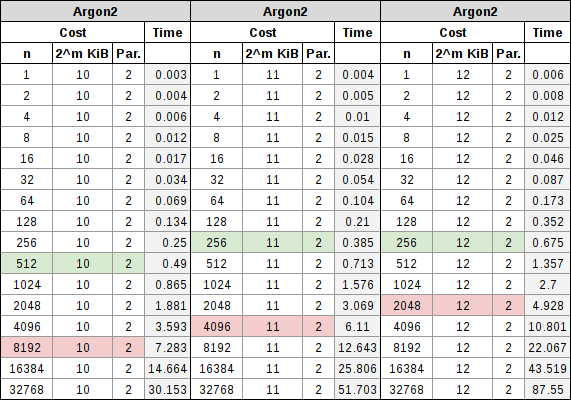
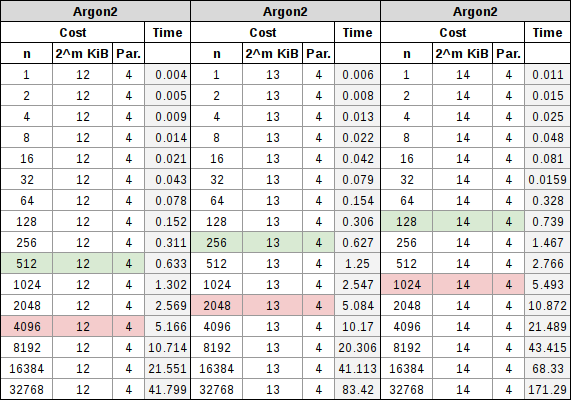
La nota a tener en cuenta en este proceso de parametrización, es que el coste de la RAM varía entre 256 KiB y 16 MiB, además del número de iteraciones y el coste de recuento del procesador. A medida que aumentamos la RAM usada en la parametrización, podremos reducir nuestro coste de iteración. Como necesitamos más subprocesos para trabajar en el hash, podemos reducir aún más esa iteración. Con lo que los dos conceptos que se tratan derivan en que, independientemente, se está tratando de apuntar 0,5 segundos para un inicio de sesión de contraseña interactivo, y 5 segundos completos para la derivación de la clave de cifrado basada en contraseña.
Conclusión
Podemos resumir el uso de estos algoritmos hash a lo siguiente: al aplicar hash a las contraseñas, ya sea para almacenarlas en el disco o para crear claves de cifrado, se deben utilizar criptográficas basadas en contraseñas, diseñadas específicamente para el problema a tratar. No se deben utilizar funciones hash de propósito general de ningún tipo, debido a su velocidad. Además, no deberían implementar su propio algoritmo de «estiramiento de claves», como el hash recursivo de su resumen de contraseña y salida adicional.
Por lo que, si tenemos en cuenta que, si el algoritmo fue diseñado específicamente para manejar contraseñas, y el coste es suficiente para cubrir las necesidades, modelo de amenaza y adversario, entonces podremos decir, sin lugar a dudas, que lo estamos haciendo bien. Realmente, no nos equivocaremos si elegimos cualquiera de ellos, simplemente tenemos que tener claro el uso que le vamos a dar, para así evitar cualquier algoritmo que no esté diseñado específicamente para contraseñas con lo que reforzaremos la seguridad sobre las mismas.
Ahora ya tenéis una idea clara de qué algoritmos se usan hoy en día, hemos explicado el funcionamiento de cada algoritmo e incluso los costes de procesamiento para que podamos tener claro cuál usar dependiendo de la situación. Lo que sí que ha quedado claro es que todos son usados para un objetivo claro en común, nuestra protección, tanto los algoritmos fijos basado en hash como los variables se usan para proteger información, ya que como sabéis la información es poder. Gracias a ellos nuestras contraseñas, archivos y transmisiones de datos está a salvo de todo agente externo que quiera conocerlas.