
Todos nosotros conocemos y hemos trabajado con sistema de archivos como NTFS en Windows, o EXT4 en Linux, sin embargo, existen otros sistemas de archivos con diferentes características, funcionamiento y rendimiento. Hoy en RedesZone os vamos a hablar en detalle sobre el sistema de archivos ZFS, el mejor sistema de archivos para servidores NAS donde la integridad de los archivos es uno de los aspectos más importantes, sin olvidar la protección de los datos frente a un ransomware o malfuncionamiento de uno de los discos. ¿Estás preparado para saberlo todo sobre ZFS?
Los archivos son la base central de los sistemas operativos. Poder crear, enviar, recibir o editar archivos, es una de las funcionalidades más demandadas de cualquier sistema. Pero esto no sería posible sin un sistema bien organizado, y con las características necesarias para que no tengamos problemas a la hora de manipular estos contenidos.
Si quieres empezar a usar el sistema de archivos ZFS para tu servidor o servidores, es importante conocer cuáles son las principales características que presenta esta opción. Además, en RedesZone te explicaremos cómo poner en marcha esta alternativa, además de cada uno de los puntos iniciales para una correcta configuración. De esta manera, el uso de este sistema de archivos no tendrá ningún tipo de complicación, ya que veremos los pasos más importantes.
¿Qué es ZFS y qué características tiene?
ZFS es un sistema de archivos que fue desarrollado originalmente por Sun Microsystems para su sistema operativo Solaris, el código fuente se publicó en el año 2005 como parte del sistema operativo OpenSolaris, pero esto hizo que ZFS pudiera utilizarse en otros sistemas operativos y entornos. En un primer momento hubo problemas con los derechos de ZFS, por lo que se decidió hacer diferentes «ports» para adaptarlo a los diferentes sistemas operativos sin tener problemas de licencias. En el año 2013 se lanzó OpenZFS bajo el paraguas de proyecto Umbrella, de tal forma que ZFS podía ser utilizado sin problemas en sistemas operativos como Linux y FreeBSD entre otros. Desde este momento, podemos encontrarnos con el sistema de archivos ZFS en FreeBSD, NetBSD, Linux como Debian o Ubuntu entre otras.
El sistema de archivos ZFS se utiliza de forma nativa en sistemas operativos basados en FreeBSD, como los populares FreeNAS o XigmaNAS, dos sistemas operativos que están orientados específicamente para servidores NAS. El fabricante QNAP con su sistema operativo QTS basado en Linux, ha estado utilizando EXT4 durante muchos años, pero recientemente ha lanzado un nuevo sistema operativo llamado QuTS Hero que permite utilizar el sistema de archivos ZFS para el almacenamiento masivo, gracias a esta decisión, podremos beneficiarnos de una gran cantidad de mejoras en la integridad de archivos y en su protección frente a posibles errores de escritura.
Actualmente, el fabricante QNAP tiene servidores NAS que únicamente soportan el sistema de archivos ZFS, todos los NAS que tienen una «h» de «Hero» en su modelo es porque disponen del sistema operativo QuTS Hero, y, por tanto, tenemos el sistema de archivos ZFS. En estos servidores NAS disponemos de memoria RAM de tipo ECC (con corrección de errores), esta característica es fundamental cuando estamos usando ZFS porque permite detectar y corregir errores antes de escribirlo en disco. ZFS hace un uso intensivo de la memoria RAM como primer caché, con el objetivo de proporcionar el mejor rendimiento en lectura y en escritura, además, si activamos la deduplicación también vamos a tener un gran consumo de memoria RAM.
Normalmente se recomienda tener 2GB de RAM por cada 1TB de datos que vayamos a utilizar en el pool, aunque podría ser menor. Por este motivo, los NAS de QNAP con QuTS Hero son capaces de soportar hasta 128GB de memoria RAM ECC, con el objetivo de almacenar una gran cantidad de información en ZFS y obtener el mejor rendimiento posible. En las últimas semanas, QNAP también ha lanzado nuevos servidores NAS que nos permiten elegir entre el sistema operativo QTS normal o QuTS Hero, de esta forma, el usuario podrá elegir entre EXT4 o ZFS como sistema de archivo para el almacenamiento de todos los datos en su servidor, estos NAS también tienen la posibilidad de instalar memoria RAM non-ECC (para EXT4) y RAM ECC si vas a elegir ZFS como sistema de archivos.
Antes de empezar a explicar las principales características de ZFS, vamos a hablar de sus «límites». ZFS se ha diseñado de tal forma que nunca tengamos limitaciones en la vida real. ZFS permite crear 248 instantáneas de forma nativa, y también permite crear hasta 248 número de ficheros en el sistema de archivos. Otros límites son los 16 exabytes para el tamaño máximo de un sistema de ficheros, e incluso 16 exabytes para el tamaño máximo de un fichero. La capacidad máxima de almacenamiento un «pool» es de 3 × 1023 petabytes, por lo que tendremos espacio más que de sobra en caso de necesitarlo, además, podremos tener hasta 264 discos en un zpool, y 264 zpools en un sistema.
Espacios de almacenamiento virtuales (Storage pools)
En ZFS existen lo que se denomina «espacios de almacenamiento virtuales», o también conocidos como vdevs, que básicamente son el dispositivo de almacenamiento, es decir, los discos duros o SSD para el almacenamiento. Con ZFS no tenemos los típicos RAID que encontramos en sistemas de archivos como EXT4, los típicos RAID 0, RAID 1 o RAID 5 entre otros, también existen aquí, pero de diferente manera.
Un «pool» puede ser de varios tipos, dependiendo de lo que nosotros queramos en cuanto a velocidad, espacio de almacenamiento e integridad de los datos en caso de que uno o varios discos fallen:
- Stripe: todos los discos se meten dentro de un «pool» y se suman las capacidades de los diferentes discos. En caso de fallo de un disco, perderemos toda la información. Este tipo de pool es como el RAID 0 pero permite incorporar múltiples discos en él.
- Mirror: todos los discos se meten dentro de un «pool» y se replican, la capacidad máxima del pool será la misma que la menor capacidad de uno de los discos. Todos los discos en el mirror están replicados, por tanto, solamente perderemos información si se rompen todos los discos del mirror. Este tipo de pool es como un RAID 1, pero permite incorporar múltiples discos en él.
- RAID Z1: todos los discos se meten dentro del pool. Suponiendo que todos los discos tengan la misma capacidad, se suma la capacidad de todos los discos menos la de uno (si tenemos 3 discos de 4TB, el espacio de almacenamiento efectivo sería de 8TB). Permite que uno de los discos se pueda romper, y la información quede intacta. El funcionamiento es como un RAID 5 que todos conocemos. Un RAID Z1 debe tener 3, 5 o 9 discos en cada vdev, por tanto, podremos tener en un vdev un total de 9 discos y que, si falla uno, no tengamos pérdida de datos, en caso de fallar un segundo disco, perderemos toda la información.
- RAID Z2: todos los discos se meten dentro del pool. Suponiendo que todos los discos tengan la misma capacidad, se suma la capacidad de todos los discos menos la de dos discos (si tenemos 4 discos de 4TB, el espacio de almacenamiento efectivo sería de 8TB). Permite que dos de los discos se puedan romper, y la información quede intacta. El funcionamiento es similar a un RAID 6 que todos conocemos. Un RAID Z2 debe tener 4, 6 o 10 discos en cada vdev, por tanto, podremos tener en un vdev un total de 10 discos y que, si fallan dos, no tengamos pérdida de datos, en caso de fallar un tercer disco, perderemos toda la información.
- RAID Z3: todos los discos se meten dentro del pool. Suponiendo que todos los discos tengan la misma capacidad, se suma la capacidad de todos los discos menos la de tres (si tenemos 5 discos de 4TB, el espacio de almacenamiento efectivo sería de 8TB). Permite que tres de los discos se puedan romper, y la información quede intacta. Un RAID Z3 debe tener 5, 7 o 11 discos en cada vdev, por tanto, podremos tener en un vdev un total de 1 discos y que, si fallan tres, no tengamos pérdida de datos, en caso de fallar un cuarto disco, perderemos toda la información.
Otras configuraciones que podremos realizar con ZFS, es definir un disco como «Hot Spare«, o también conocido como «Repuesto», para que, en caso de fallo de un disco, automáticamente entre en funcionamiento este disco de respaldo y comience el proceso de resilvering (regeneración de los datos utilizando este nuevo disco que acabamos de introducir al pool). También tenemos la posibilidad de definir un disco como «caché«, que básicamente es activar el L2ARC y tener un mayor rendimiento, esto es ideal si lo utilizamos con un SSD rápido, de tal forma que aumentemos el rendimiento global del sistema, si vas a utilizar un HDD normal, no notarás ninguna mejoría e incluso podría empeorar el rendimiento. Por último, también tenemos la posibilidad de definir un disco como «LOG» (SLOG ZFS Intent Log) para almacenar los registros de escritura que deberían haber ocurrido, esto es de ayuda en caso de un corte en el suministro eléctrico.
ZFS se ayuda del caché que hemos comentado anteriormente para acelerar enormemente las transferencias de datos, tanto en lectura como escritura, además, no solamente mejoraremos al lectura y escritura secuencial sino también la lectura y escritura aleatoria.
Sistemas de ficheros ligeros (dataset)
Los dataset son realmente los sistemas de ficheros de ZFS, es lo que hay dentro de un espacio de almacenamiento de ZFS. Para crear un dataset es requisito imprescindible haber creado antes un «pool», de lo contrario no es posible crearlo. Existen dos tipos de dataset diferentes:
- Filesystem: es el tipo de dataset por defecto, es el que se utiliza para almacenar los archivos, carpetas etc. Se puede establecer directamente el punto de montaje, sin editar el típico fstab de sistemas Linux.
- ZVOL: es un dataset que representa a un dispositivo por bloques, también lo podemos encontrar en los diferentes sistemas operativos como «Volumen». Este dataset permite crear un dispositivo por bloques, y posteriormente darle formato con sistemas de archivos como EXT4.
Algunas de las características más importantes de un dataset (filesystem) son que permite configurar cuotas, cuota de disco reservada, gestión de permisos con avanzadas listas de control de acceso (ACL), e incluso permite características muy avanzadas como las siguientes:
- Deduplicación (dedup): la deduplicación es una técnica que consiste en eliminar copias duplicadas de datos repetidos. No se le podría llamar «comprimir», pero sí es cierto que, si realizamos deduplicación, el tamaño final de un conjunto de datos es claramente menor. Esta técnica se utiliza para optimizar el almacenamiento de datos en disco. ZFS hace la deduplicación de manera nativa, por tanto, es muy eficiente, pero para que funcione correctamente necesita una gran cantidad de memoria RAM: por cada 1TB de dataset deduplicado, se necesitan unos 16GB de memoria RAM. Teniendo en cuenta que hoy en día es mucho más barato el espacio de almacenamiento (discos duros) que la RAM, es aconsejable no usar la deduplicación, a no ser que sepas lo que estés haciendo.
- Compresión: nativamente ZFS permite hacer uso de diferentes algoritmos de compresión, con el objetivo de ahorrar espacio de almacenamiento en el dataset, y, por tanto, en el «pool». El algoritmo de compresión LZ4 es el estándar actualmente y el más recomendado en la mayoría de situaciones, también se pueden utilizar otros como LBJB, e incluso GZIP con diferentes niveles de compresión. No obstante, muy pronto veremos ZSTD que es un nuevo algoritmo de compresión para ZFS. ZSTD es un algoritmo de compresión general, moderno y de alto rendimiento, creado por la misma persona que LZ4, su objetivo es proporcionar niveles de compresión similares a GZIP, pero con mejor rendimiento. Otra característica interesante de ZSTD es que permite seleccionar diferentes niveles de compresión/rendimiento para adaptarse a las necesidades de los administradores.
- Instantáneas (Snapshots): las instantáneas nos permiten guardar una «foto» del estado del sistema de archivos en un determinado momento, con el objetivo de proteger la información si sufrimos el ataque de un ransomware, o que directamente eliminamos un archivo cuando no deberíamos haberlo hecho. Aunque fabricantes como QNAP o Synology tienen instantáneas y usan EXT4, los snapshots de ZFS son nativos, por lo que su funcionamiento es mucho más eficiente. ZFS nos permite visualizar los datos de estas instantáneas sin revertirlas, revertir todos los cambios, e incluso «clonar» estos snapshots que hemos realizado. Esto de los «clones» permiten tener dos sistemas de ficheros independientes que se crear compartiendo un conjunto común de bloques. El número de snapshots que podemos realizar con ZFS son de 248, es decir, se podría decir que tenemos instantáneas ilimitadas.
ZFS no sobreescribe datos debido al modelo Copy-on-write del que hablaremos posteriormente, por tanto, tomar una instanténea simplemente significa no liberar los bloques utilizados por versiones antiguas. Las instanténas se toman de manera muy rápida y son realmente eficientes desde el punto de vista del espacio, no ocupan nada a no ser que modifiques un dato del que se ha realizado el «snapshot». Es decir, no hay una duplicación de datos, los datos el snapshot y los que hay en producción se comparten, únicamente al modificarlo es cuando empieza a aumentar la ocupación.
Auto reparación (Self-healing)
Una de las características más importantes de ZFS es la auto reparación, anteriormente hemos hablado de que existen pools de tipo «mirror» y también RAID-Z, con paridad simple, doble o triple. Un aspecto muy importante es que ZFS no tiene el defecto de «write-hole», esto puede ocurrir cuando se produce un fallo en el suministro eléctrico durante la escritura, esto hace que sea imposible determinado qué bloques de datos o bloques de paridad se han escrito en los discos y cuáles no. En esta situación de error catastrófico, los datos de paridad no coinciden con el resto de datos del espacio de almacenamiento, además, no se puede saber qué datos son incorrectos: los de paridad, o los datos del bloque.
Todos los datos en ZFS son hasheados previamente a su escritura en el pool, el algoritmo del hash se podría configurar a la hora de crear el dataset. Una vez que se ha escrito el dato, el hash es comprobado para verificar que se ha escrito correctamente y no ha habido problemas en la escritura. ZFS permite comprobar la integridad de los datos de forma fácil haciendo uso de estos datos hasheados. En caso de no corresponderse los datos con el hash, lo que se hace es buscar en el «mirror» o calcular los datos a través del sistema de paridad (RAID-Z) para proceder con su comprobación a nivel de hash. Si los datos del hash con iguales, se procede con la corrección de los datos en el bloque. Todo esto se realiza de forma totalmente automática.
Copy-on-write
ZFS utiliza una arquitectura copy-on-write, gracias a esto, evitamos los problemas derivados del write-hole que hemos explicado anteriormente. El CoW es una de las principales características de ZFS. El funcionamiento consiste en que todos los punteros a bloques de un sistema de ficheros contienen un checksum, el cual se comprueba al leer el bloque. Los bloques que contienen datos activos no se sobrescriben nunca, lo que se hace es reservar un nuevo bloque, y los datos modificados se escriben en él directamente. Para hacerlo más rápido y eficiente, se suelen agregar varias actualizaciones para realizar posteriormente las transacciones, e incluso se utiliza un ZIL (ZFS Intent Log).
La parte negativa de esto, es que produce una alta fragmentación en los pools, y no hay posibilidad actualmente de realizar una desfragmentación. Si tu pool está formado por SSD, no notarás demasiado la pérdida de rendimiento por la propia naturaleza de los SSD, pero si haces uso de HDD es posible que sí lo notes. En nuestro caso, tenemos una fragmentación superior al 25% después de varios años de utilización:
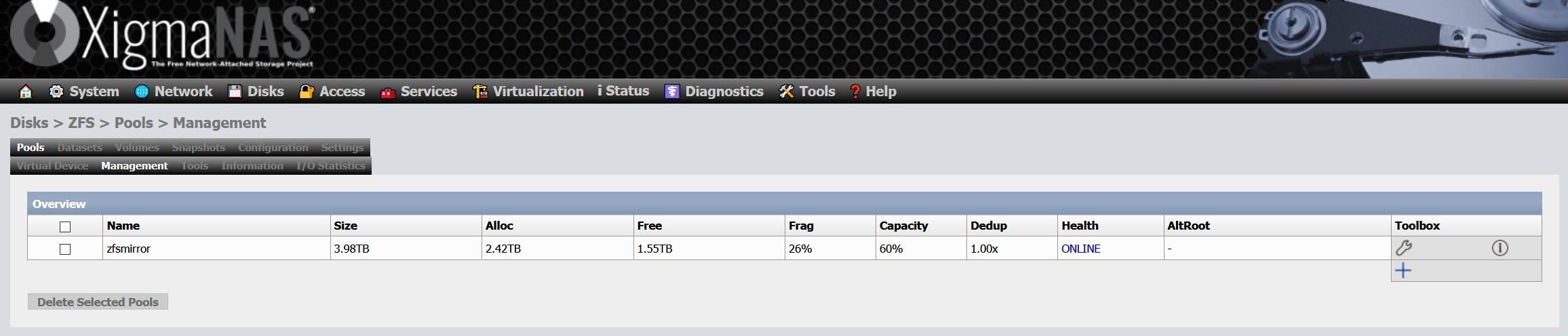
La única forma de realizar una desfragmentación al pool, es copiando los datos a otro medio, eliminar el pool y crearlo nuevamente. Es decir, no hay una forma de desfragmentar un pool en ZFS, al menos de momento.
Dynamic Striping
ZFS distribuye los datos que escribimos dinámicamente en todos los dispositivos virtuales (vdev), con la finalidad de aumentar el rendimiento al máximo. La decisión de dónde colocar los datos se realiza en el momento de la escritura. Esto mejora mucho en pools de tipo mirror y RAID-Z, y, además, elimina de manera eficaz el problema del write-hole que hemos visto anteriormente.
Otra característica interesante es que ZFS utiliza bloques de tamaño variable de hasta 128K, el administrador puede configurar el tamaño máximo de bloque utilizado, ideal para adaptarse a las necesidades de lo que va a escribir en el pool, pero se puede adaptarse automáticamente. En el caso de usar compresión, se usan estos tamaños de bloque variable para que sea mucho más eficiente con el espacio.
¿Qué problemas se pueden presentar?
A pesar de que ZFS es un sistema de archivos muy robusto, con integridad de datos y muchas características avanzadas, también puede presentar algún desafío. Por esto, es importante conocer a que te puedes enfrentar al hacer uso de este sistema en particular. Algunos de estos son:
- Uso de la memoria: Si revisamos la función de caché de ARC, nos encontramos con un sistema que puede consumir una cantidad significativa de memoria RAM. Estos sistemas con una memoria insuficiente, pueden experimentar problemas de rendimiento en algunos casos.
- Fragmentación: A pesar de que la fragmentación es manejada de una forma más eficaz que otros sistemas de archivos, aún puede generar problemas. Especialmente cuando son pools de espacios limitados.
- Expansión de almacenamiento: Algo que ZFS no permite en comparación con otros sistemas de archivos, es agregar de forma sencilla un solo disco vdev (conjunto de discos) ya existente en ZFS. Por lo general, las expansiones requieren agregar otros vdev a los pools. Por otro lado, eliminar uno tampoco era una opción. Pero esto se ha corregido en las versiones más recientes de este sistema de archivos. Abordando con éxito esta limitación.
- Licencia y distribución: Muchas licencias pueden ser incompatibles, y en el caso de ZFS no se incluye de forma predefinida en los kernel de Linux. Esto es posible que llegue a complicar un poco la instalación y las actualizaciones de los sistemas basados en Linux.
- Desgaste de los discos: Si se da uso de discos SSD para las cachés ZIL o L2ARC, las operaciones de escritura van a aumentar. Por lo cual puede conllevar una aceleración del desgaste de estos discos de estado sólido.
- Reparaciones pool: Recuperar un pool ZFS dañado cuando no hay respaldos o redundancia, puede ser muy complejo. Incluso en algunos casos, lo más probable es que llegue a ser imposible recuperar ese contenido.
Características y mejoras de OpenZFS 2.0
OpenZFS 2.0 ya es una realidad, la última versión de este sistema de archivos de alto rendimiento y gran integridad de datos, se ha actualizado con novedades muy interesantes. Lo primero que debemos indicar, es que OpenZFS 2.0 es compatible con FreeBSD 12 en adelante, y también es compatible con Linux Kernel entre las versiones 3.10 y 5.9, por tanto, tendremos una gran compatibilidad para exprimir todas sus novedades.
Algunas de las múltiples mejoras que han incorporado a este sistema de archivos, son las siguientes:
- Resilver secuencial de los datos: la función de resilver secuencial, permite reconstruir un mirror vdev en muy poco tiempo en comparación con el resilvering tradicional. La redundancia completa se restaura lo más rápido posible, y posteriormente el pool se limpia automáticamente para comprobar todas las sumas de comprobación.
- L2ARC persistente: esta función hace que el dispositivo L2ARC para caché de datos sea persistente, aunque reiniciemos el equipo, esto hace que eliminemos el tiempo de preparación de caché habitual que normalmente necesitamos después de importar el grupo.
- Compresión ZST integrada: en esta nueva versión de ZFS disponemos del algoritmo de compresión Zstandard, un algoritmo de compresión moderno y que tiene un alto rendimiento, además, es un algoritmo de compresión «general», por lo que funciona muy bien independientemente de los datos que vayamos a comprimir. Este algoritmo proporciona niveles de compresión similares o mejores que GZIP, pero con un rendimiento muchísimo mejor. Podremos seleccionar el nivel de compresión para permitir balancear el rendimiento/compresión dependiendo de nuestras necesidades.
- Incorporación de «Redacted streams» en recepción y envío, esta característica permite enviar subconjuntos de datos a un sistema de destino. Permite a los usuarios ahorrar espacio al no replicar datos sin importancia, e incluso podremos seleccionar el excluir información.
Otros cambios introducidos en esta nueva versión están relacionados con los comandos, se han añadido algunos comandos nuevos, y se han modificado algunos que ya teníamos, para adaptarlos a las nuevas características de ZFS. Si queréis saber en detalle los cambios en los comandos ZFS os recomendamos visitar el GitHub oficial. Otras mejoras incorporadas son la compatibilidad para preasignar espacio, se han reorganizado las páginas man del tutorial oficial de ZFS, se ha habilitado un módulo PAM para cargar automáticamente claves de cifrado ZFS y mucho más. Por último, se ha mejorado enormemente el rendimiento, y es que ahora el borrado de los clones de los snapshots es mucho más rápido con zfs destroy, también es mucho más rápido el envío/recepción de pequeños registros, se ha mejorado la escalabilidad del recurso compartido de zfs, la gestión de memoria y el ARC es mucho más eficiente, también se ha mejorado el rendimiento AES-GCM para proteger nuestros datos con una capa de cifrado.
Cómo instalar y poner en marcha ZFS
ZFS se encuentra instalado en sistemas operativos basados en FreeBSD, como, por ejemplo, XigmaNAS o FreeNAS. El sistema de archivos por defecto en estos sistemas operativos es UFS, pero tenemos la opción de utilizar ZFS como sistema de archivos del sistema. Por lo que es fácil de comenzar a usar si tienes un equipo con este software en concreto.
No obstante, lo más recomendable es usar ZFS como sistema de archivos del conjunto de almacenamiento donde vayamos a tener todos y cada uno de nuestros archivos, es aquí donde verdaderamente podremos sacarle el máximo partido. En estos sistemas operativos orientados a NAS, no tendremos que ejecutar ningún comando debido a que todo se hace con la interfaz gráfica de usuario, sin necesidad de tocar nada más. Otros sistemas operativos como Debian, Ubuntu, Linux Mint y otros, necesitaremos instalar ZFS de manera manual.
A continuación, os vamos a enseñar cómo configurar y poner en marcha ZFS en un sistema operativo XigmaNAS (basado en FreeBSD), el procedimiento es similar a FreeNAS ya que estamos usando el mismo sistema de archivos. También os enseñaremos cómo instalarlo en sistemas operativos como Debian, aunque aquí tendremos que hacerlo todo a través de consola de comandos.
Configuración y puesta en marcha de ZFS en XigmaNAS
Para la realización de este tutorial hemos utilizado VMware para virtualizar XigmaNAS, y hemos creado un total de 6 discos virtuales. El primer disco virtual de 20GB de capacidad es para instalar el propio sistema operativo, y está en formato UFS que es el nativo de FreeBSD. Los otros 5 discos con 100 GB cada uno, está orientado al espacio de almacenamiento para el sistema de archivos ZFS, y estarán formateados como ZFS.
Una vez se tenga en cuenta estos puntos, pasaremos a ver los primeros pasos que se deben seguir para hacer uso de este sistema de archivos desde cero. Por lo que podrás seguir desde el principio el proceso al completo para su puesta en marcha:
Paso 1: Formatear los discos en formato ZFS para añadirlos a un pool
El primer paso es formatear los discos en formato ZFS para añadirlos a un pool, para ello, nos vamos a «Discos / Administración«.
Dentro de este menú, nos vamos a la pestaña de «Opciones del HDD» y pinchamos en «Importar Discos – Importar», para importar todos los discos que hemos configurado en el servidor.
Nos aparecerán todos los discos sin formato, porque los acabamos de añadir, pero también nos aparecerá el disco del sistema operativo en formato UFS.
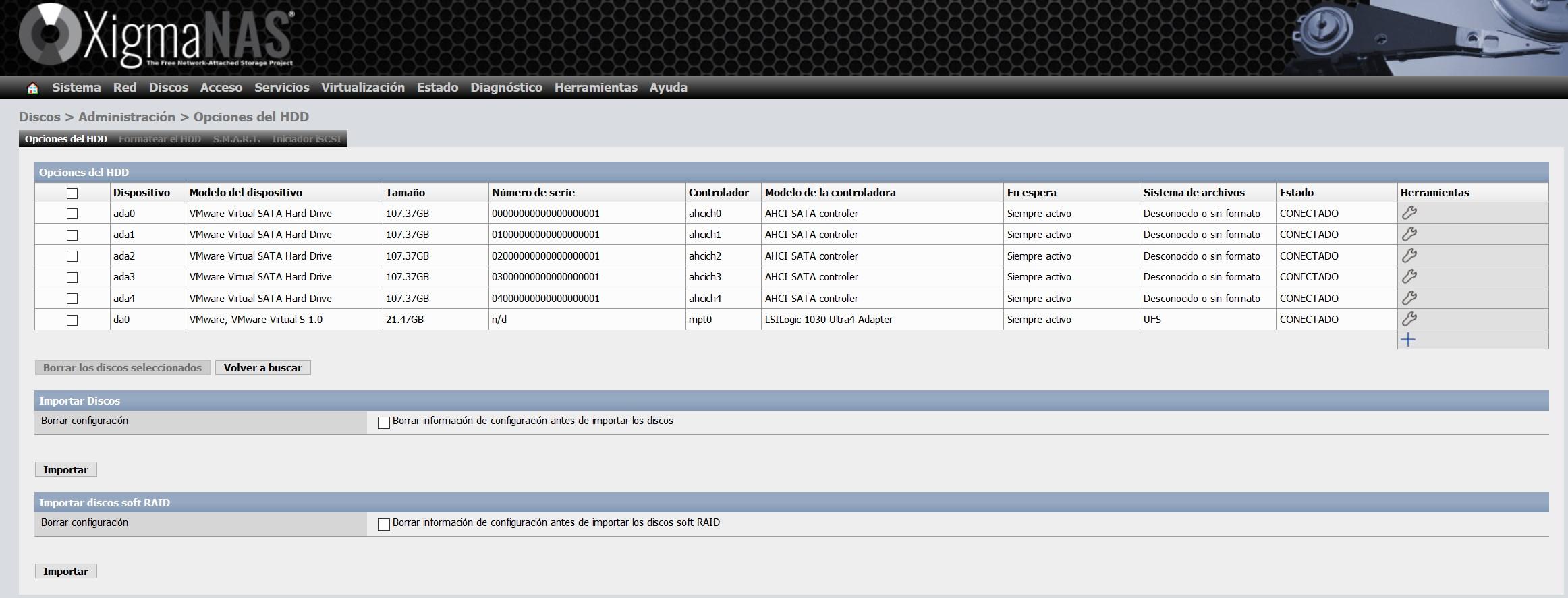
En la pestaña de «Formatear HDD» seleccionamos todos los discos, y seleccionamos «Sistema de archivos: Almacenamiento ZFS en la agrupación de dispositivos (Pool)«.
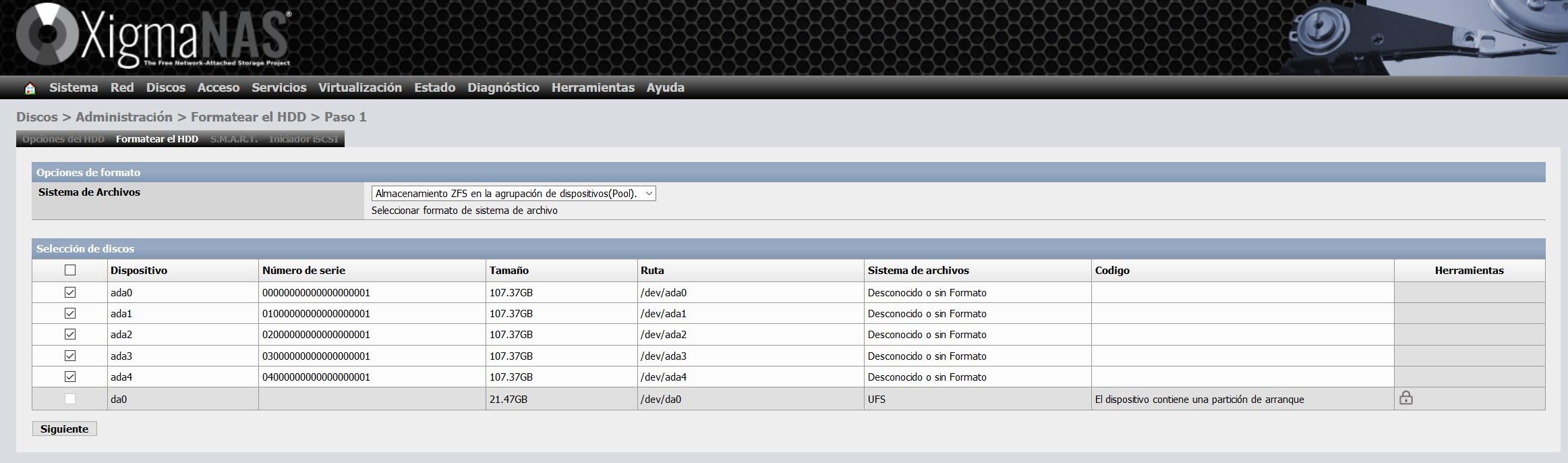
En el asistente de configuración para formatearlo, podemos darles una etiqueta de volumen, tal y como podéis ver a continuación:
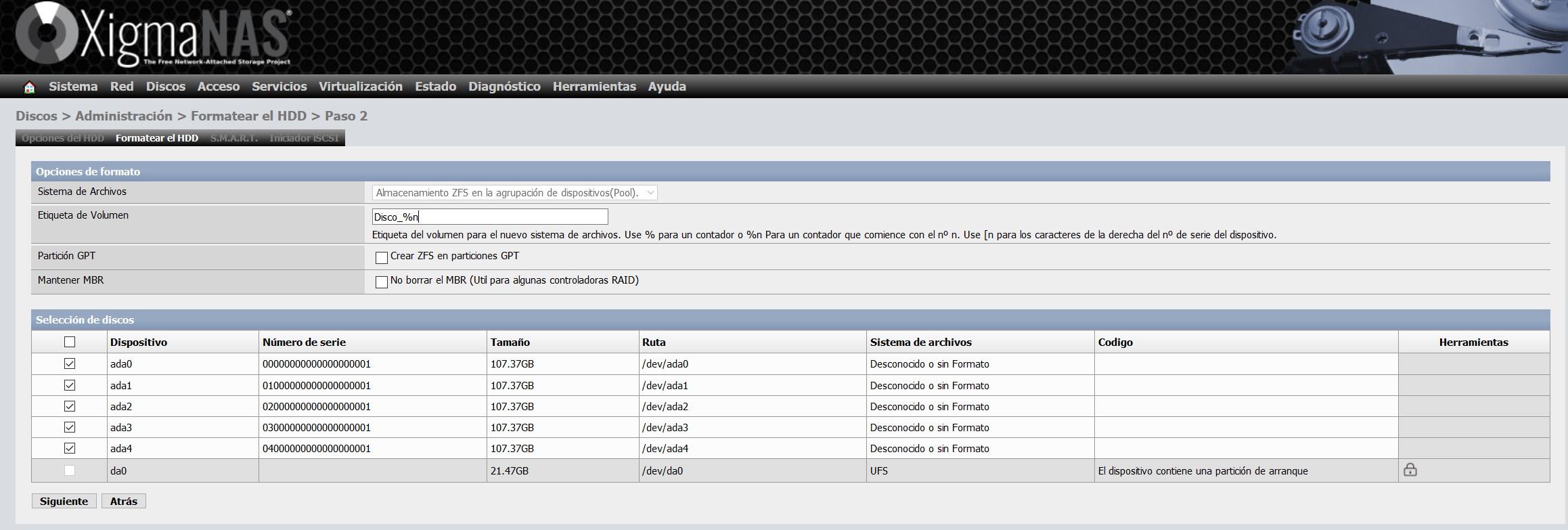
Pinchamos en siguiente y ya habremos formateado todos los discos en formato ZFS, listo para añadirlos a un pool ZFS.
Paso 2: Creación del dispositivo virtual vdev ZFS
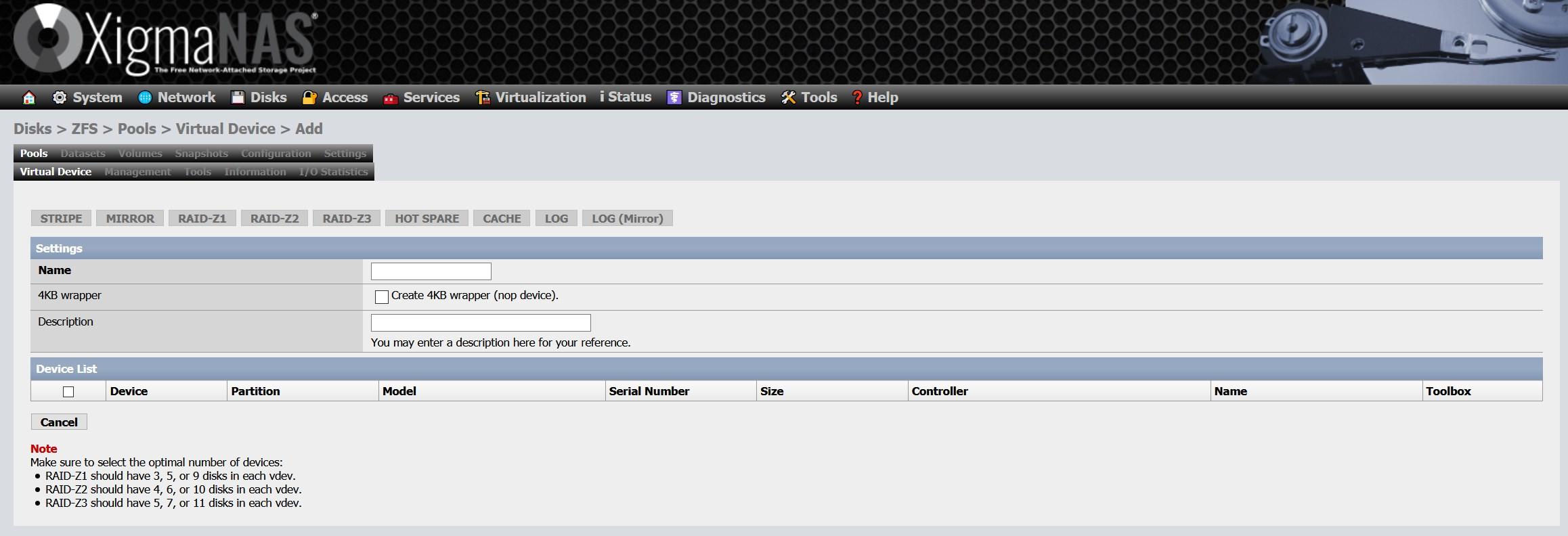
Ahora teneos que irnos a «Discos / ZFS» y accederemos a la sección de «Agrupaciones de dispositivos (pools)» en la parte de «Dispositivo virtual». En esta sección pinchamos en el «+» que tenemos en la parte de la derecha.

Aquí lo que tendremos que hacer es seleccionar todos los discos que queremos incorporar el vdev, dependiendo del número de discos que agreguemos, tendremos la posibilidad de configurar un «Stripe», «Mirror» y los diferentes RAIDZ. Nosotros hemos elegido los cinco discos, por tanto, podremos crear los cinco tipos.
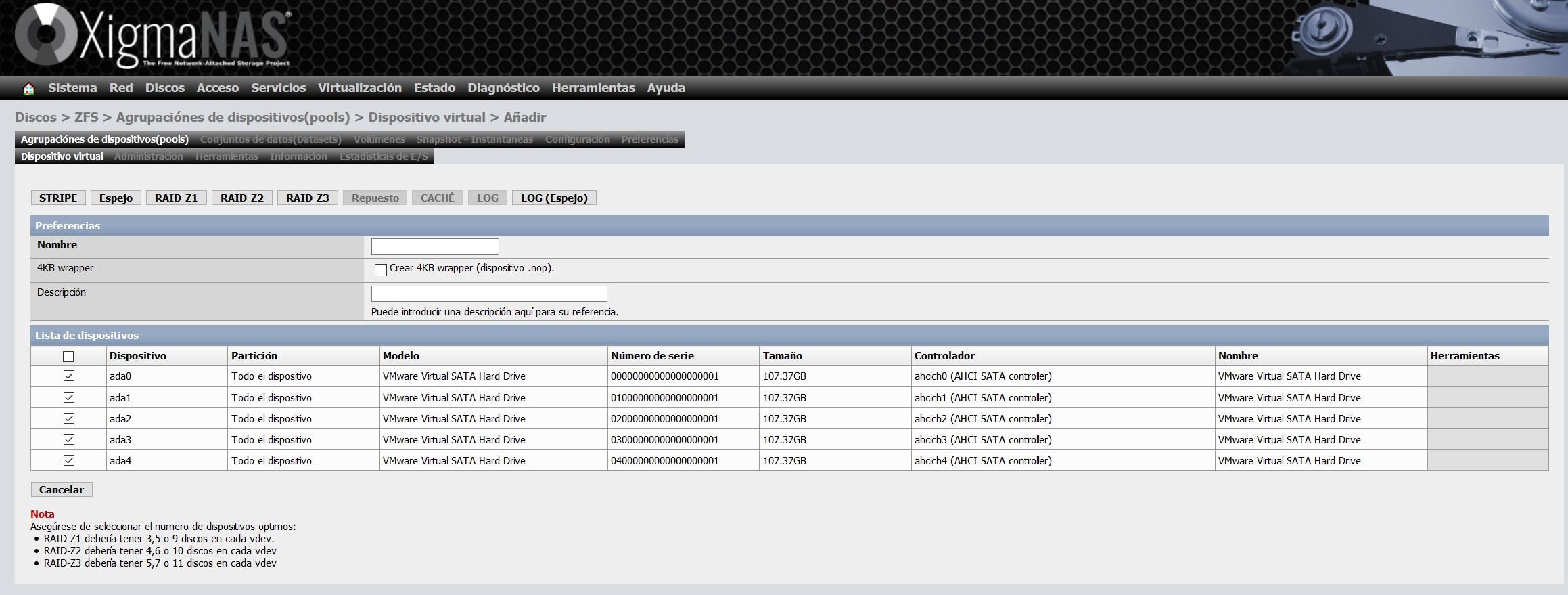
Nosotros hemos elegido la opción de «Espejo», o también conocido como «Mirror». Con esta opción tendremos en los cinco discos exactamente la misma información.
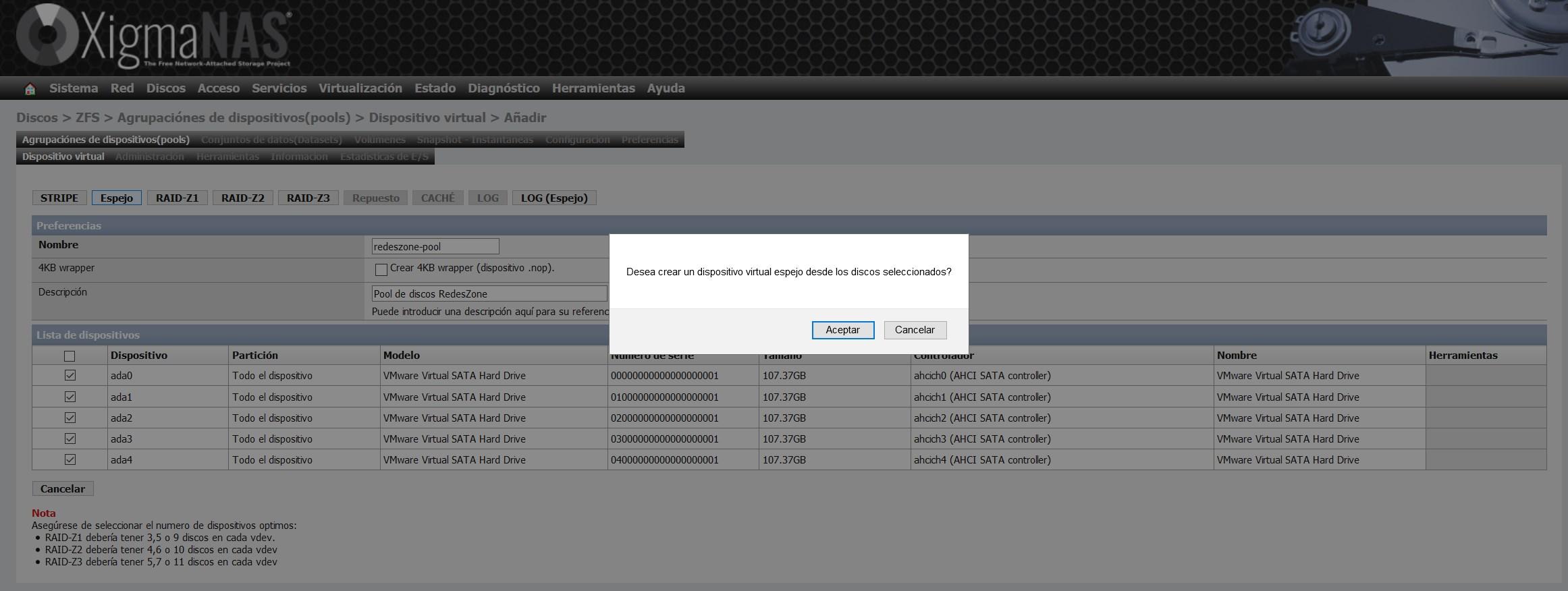
Una vez que hayamos creado el dispositivo virtual, nos aparecerá en el listado de dispositivos virtuales, tal y como podéis ver aquí:
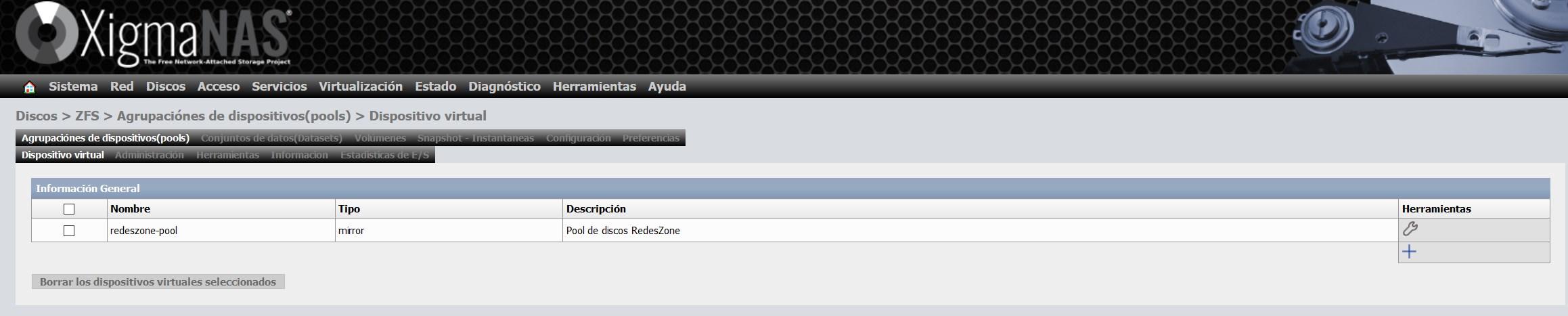
Paso 3: Configurar el pool y darle un nombre
Una vez que hayamos creado el vdev, debemos irnos a «Administración», y pinchar en «+» para dar formato a este vdev y poder utilizarlo posteriormente con un Dataset o Volumen.

Le tenemos que dar un nombre, y también podremos definir el punto de montaje que nosotros queramos, el punto de montaje predeterminado es /mnt.
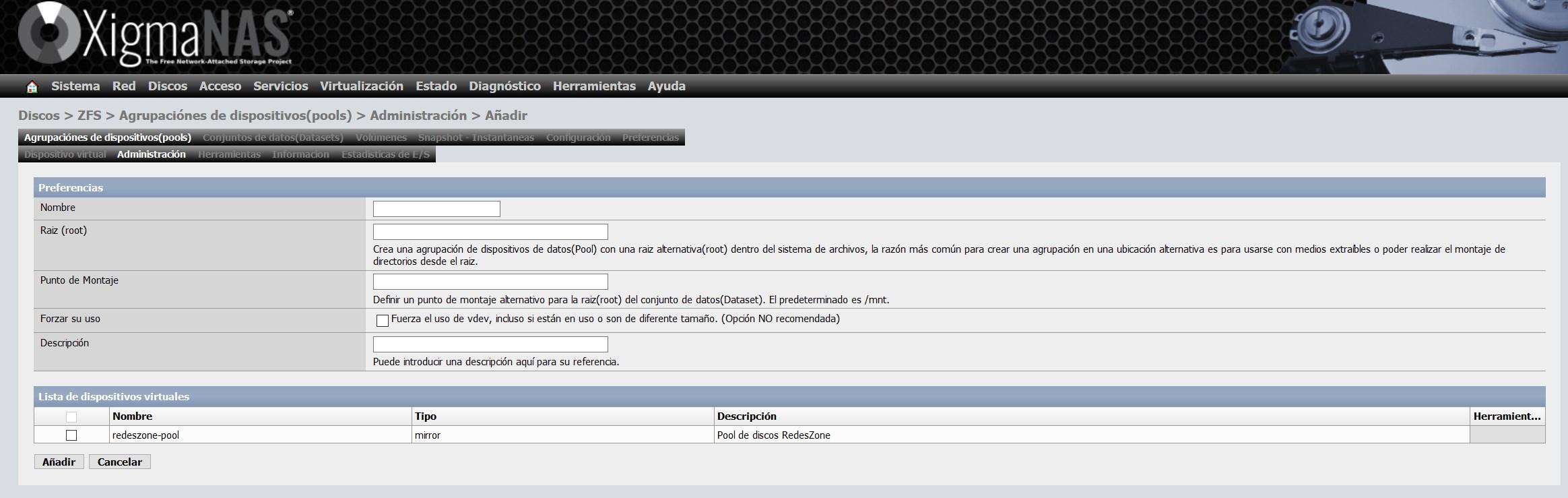
Le vamos a dar el nombre de zfsalmacen y elegimos el vdev que hemos creado anteriormente, tal y como podéis ver aquí:
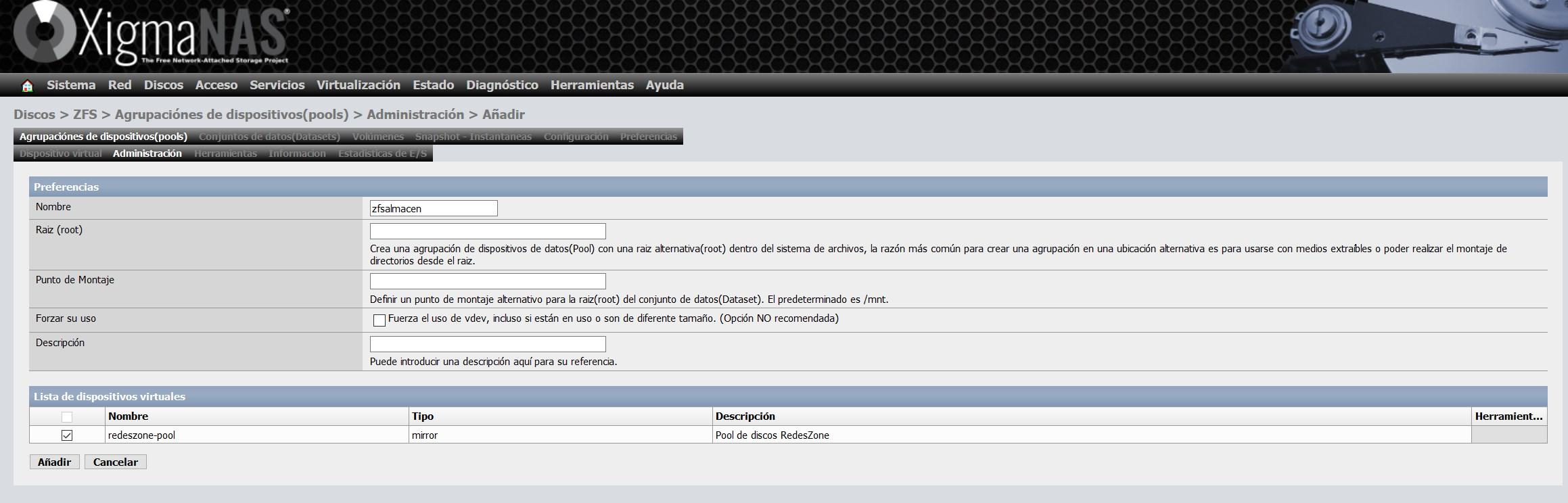
Una vez que lo hayamos creado, nos aparecerá el tamaño total, tamaño libre, fragmentación etc.
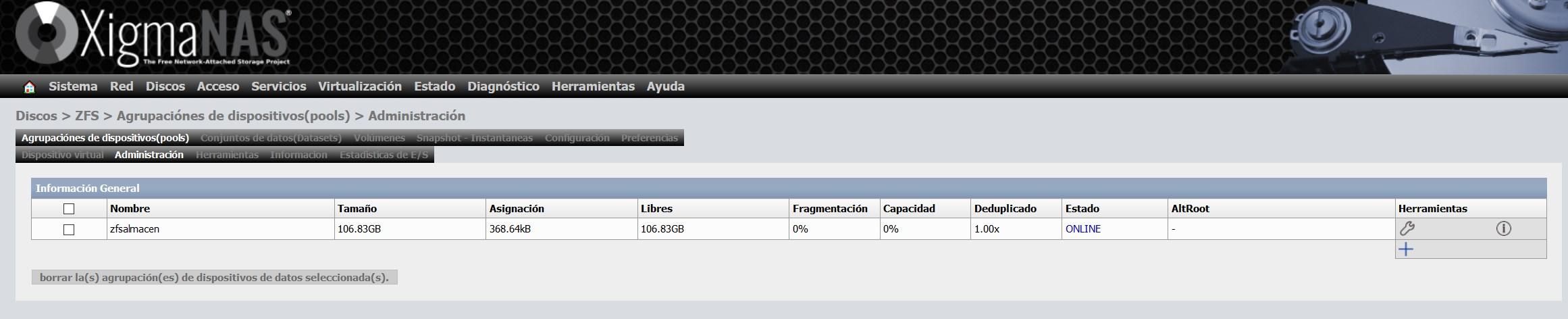
Una sección muy importante de XigmaNAS es la sección de «Herramientas», aquí tendremos diferentes asistentes de configuración para realizar diferentes acciones, todo esto lo podemos hacer manualmente mediante comandos, pero con esta interfaz gráfica de usuario podremos hacerlo en un par de clicks. Lo que nos permite realizar XigmaNAS es todo lo siguiente:
- Actualizar el nucleo ZFS y añadir soporte de nuevas caracteristicas a la agrupacion de dispositivos (Pool)
- Agrega un dispositivo de reserva a la agrupación de dispositivos de datos (Pool)
- Agrega un dispositivo para CACHÉ a la agrupación de dispositivos de datos (Pool)
- Agrega un dispositivo para LOG a la agrupación de dispositivos de datos (Pool)
- Conecta un dispositivo para datos
- Desconecta un dispositivo de datos de un espejo
- Desplegar la historia de comandos ZFS
- Elimina los errores del dispositivo
- Eliminar la etiqueta ZFS del dispositivo
- Elimina una agrupación de dispositivos de datos (Pool).
- Exportar una agrupación de dispositivos (pool) ZFS desde el sistema
- Generar un identificador unico para la agrupación de dispositivos (pool)
- Listar o importar agrupaciónes de dispositivos (pools)
- Pone el disco fuera de linea
- Ponga un dispositivo en linea
- Reemplazar un dispositivo
- Revisar (Scrub) la agrupación de dispositivos (pool)
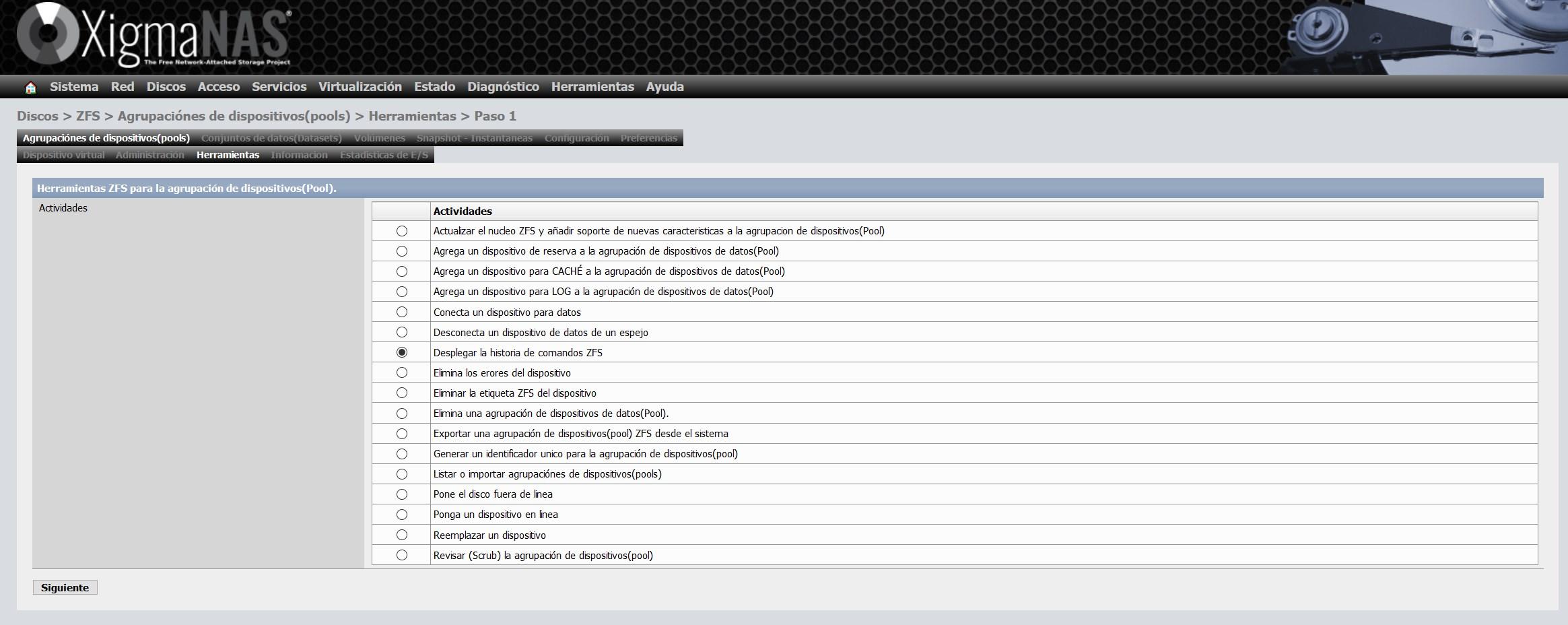
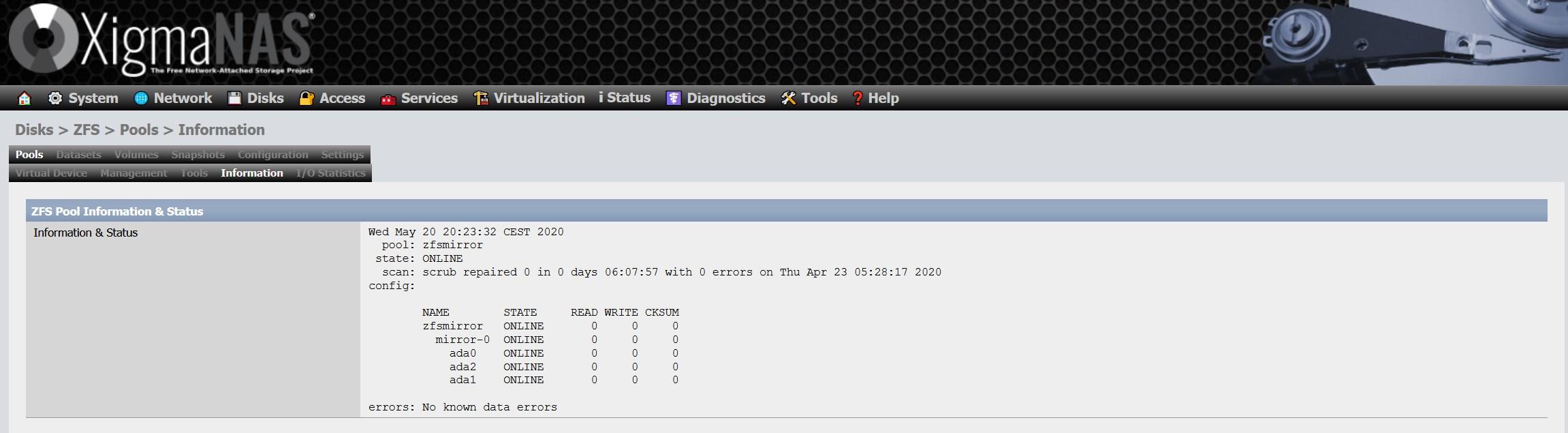
En la sección de «Información» podremos ver el estado general del ZFS, el tipo de vdev elegido y también todos los discos que tenemos en el pool. Un detalle importante es que es posible que no tengamos el ZFS actualizado a la última versión en los propios discos, si nos sale ese aviso, tendremos que realizar una actualización que es muy sencilla.
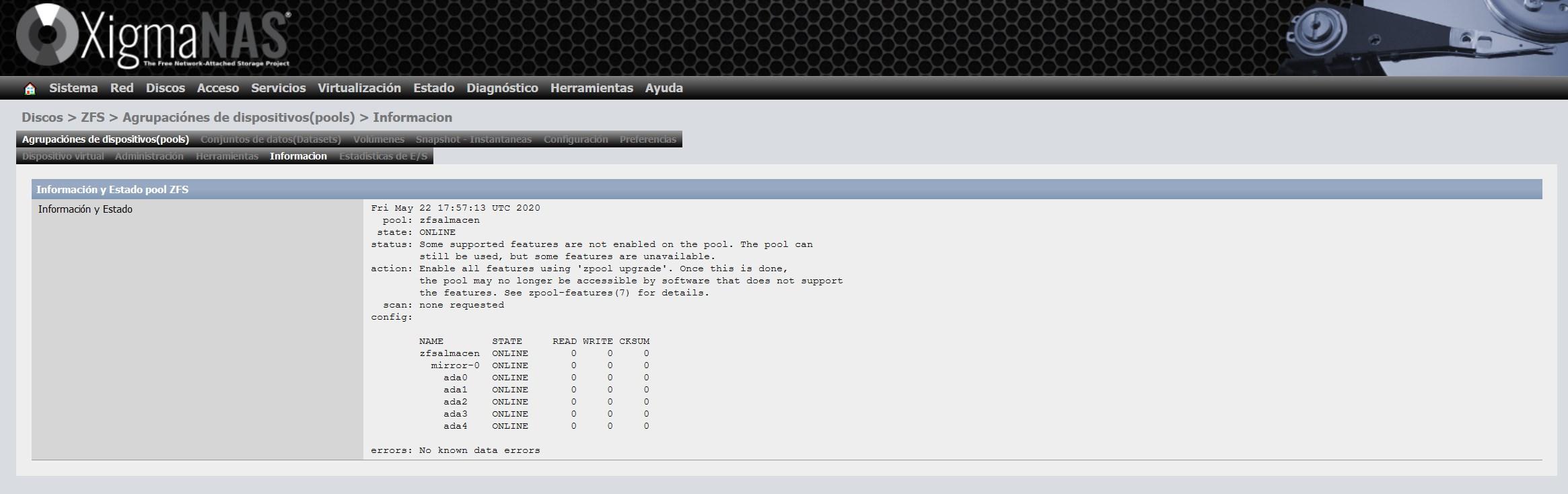
Para actualizarlo, nos vamos a la sección de «herramientas» y seleccionamos la opción «Actualizar el núcleo ZFS y añadir soporte de nuevas características a la agrupación de dispositivos (Pool)» y seguimos con el asistente para actualizarlo
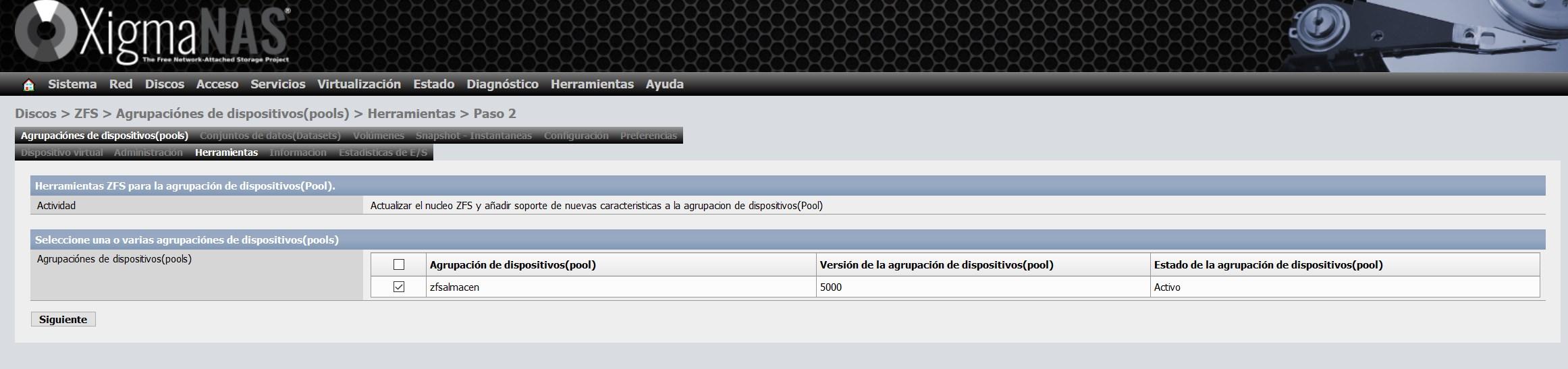
En cuanto lo hayamos actualizado, no nos saldrá ningún aviso, tal y como podéis ver aquí:
Paso 4: Creación del dataset o volumen
Crear un dataset es realmente sencillo, nos vamos a «Conjunto de datos (dataset)» y pinchamos en la tecla «+»:

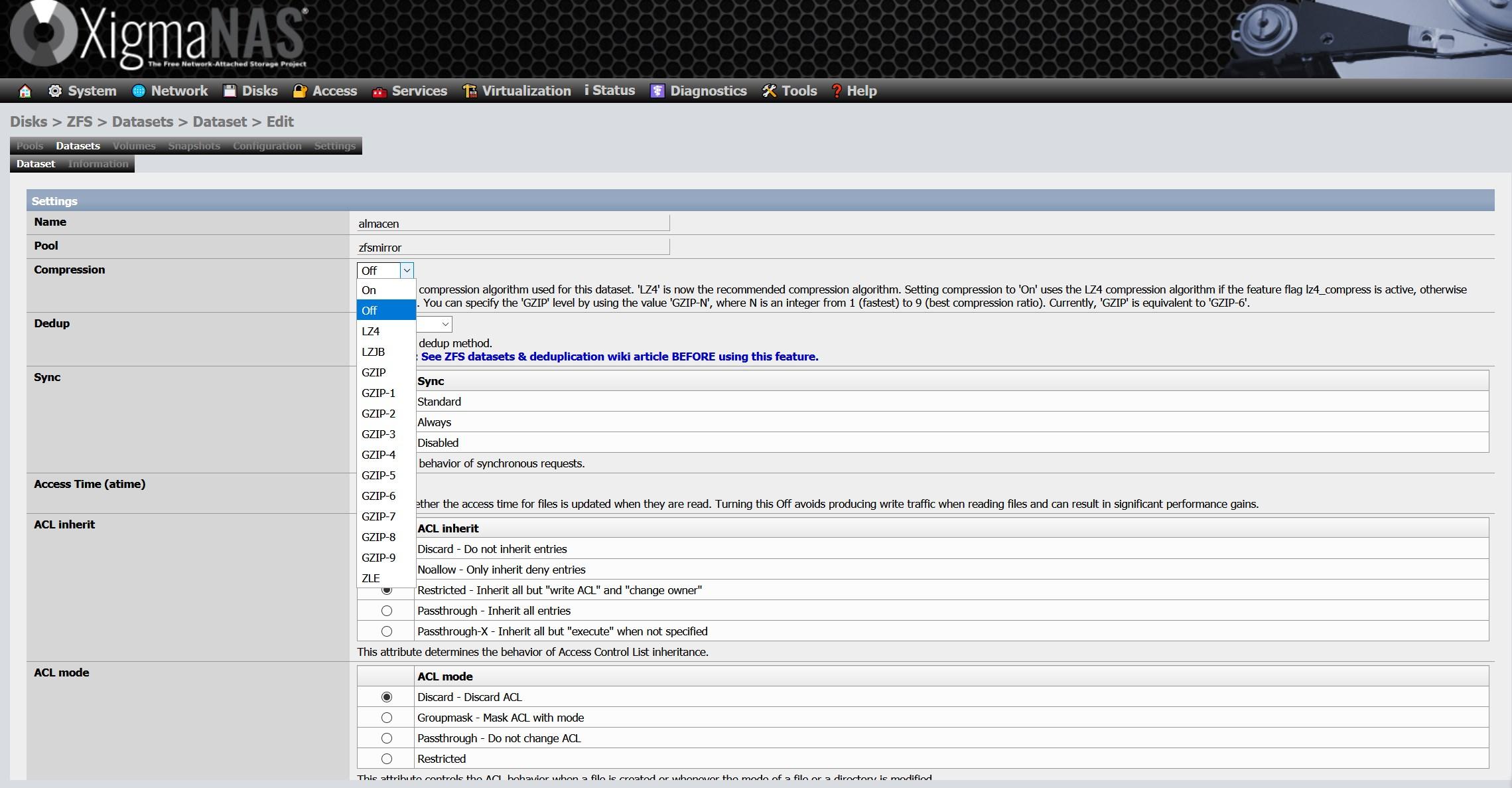
Dentro de la configuración del dataset, tenemos que elegir un nombre, y también el pool donde queremos crear el dataset. Nosotros únicamente tenemos un pool creado, así que no tiene pérdida. Aquí es donde podremos configurar la compresión en tiempo real, el deduplicado, la sincronización, las ACL y muchos más parámetros avanzados.
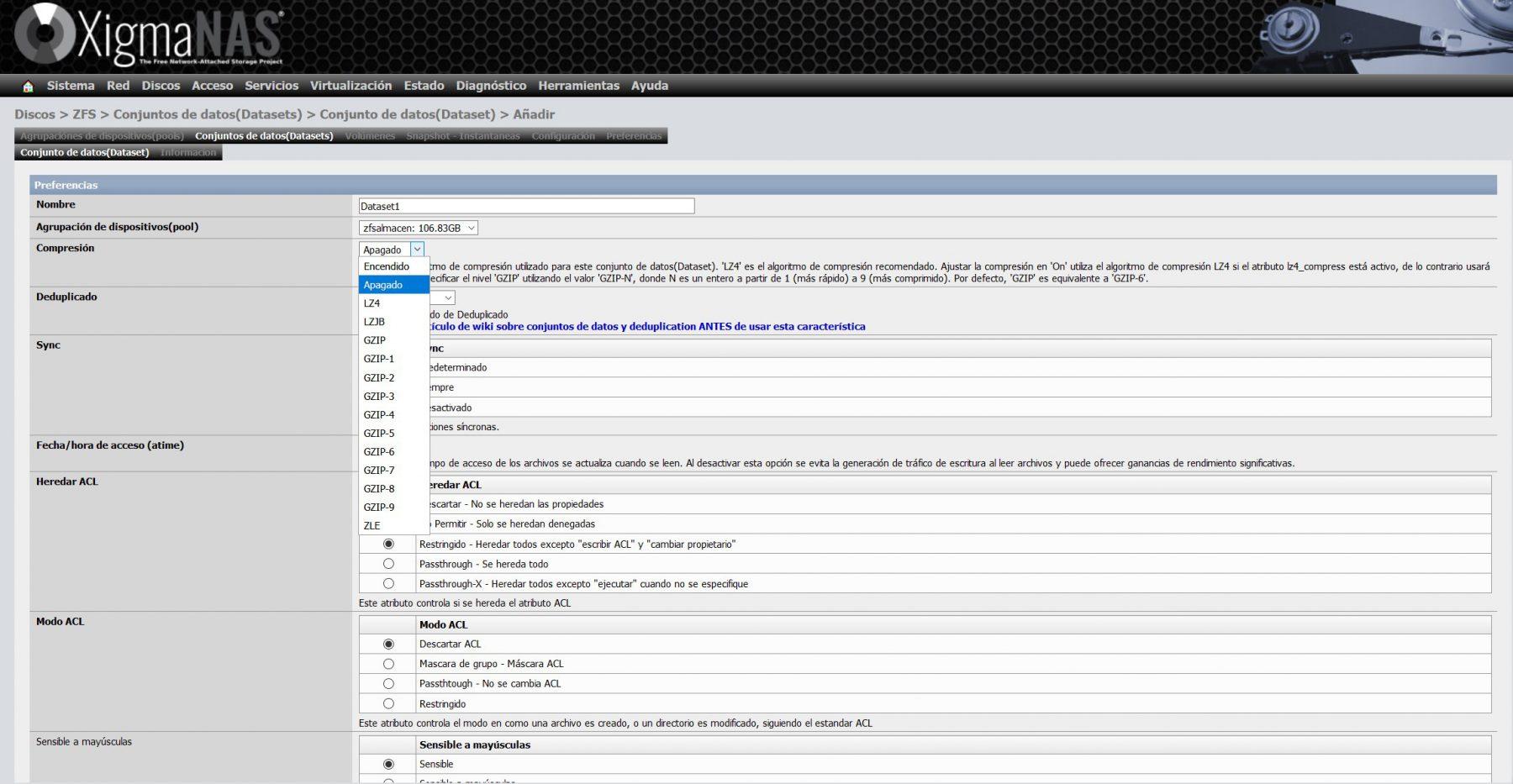
Debemos recordar que, si seleccionamos la opción de deduplicación, consumirá una gran cantidad de memoria RAM, el propio XigmaNAS nos avisa de esto en su wiki.
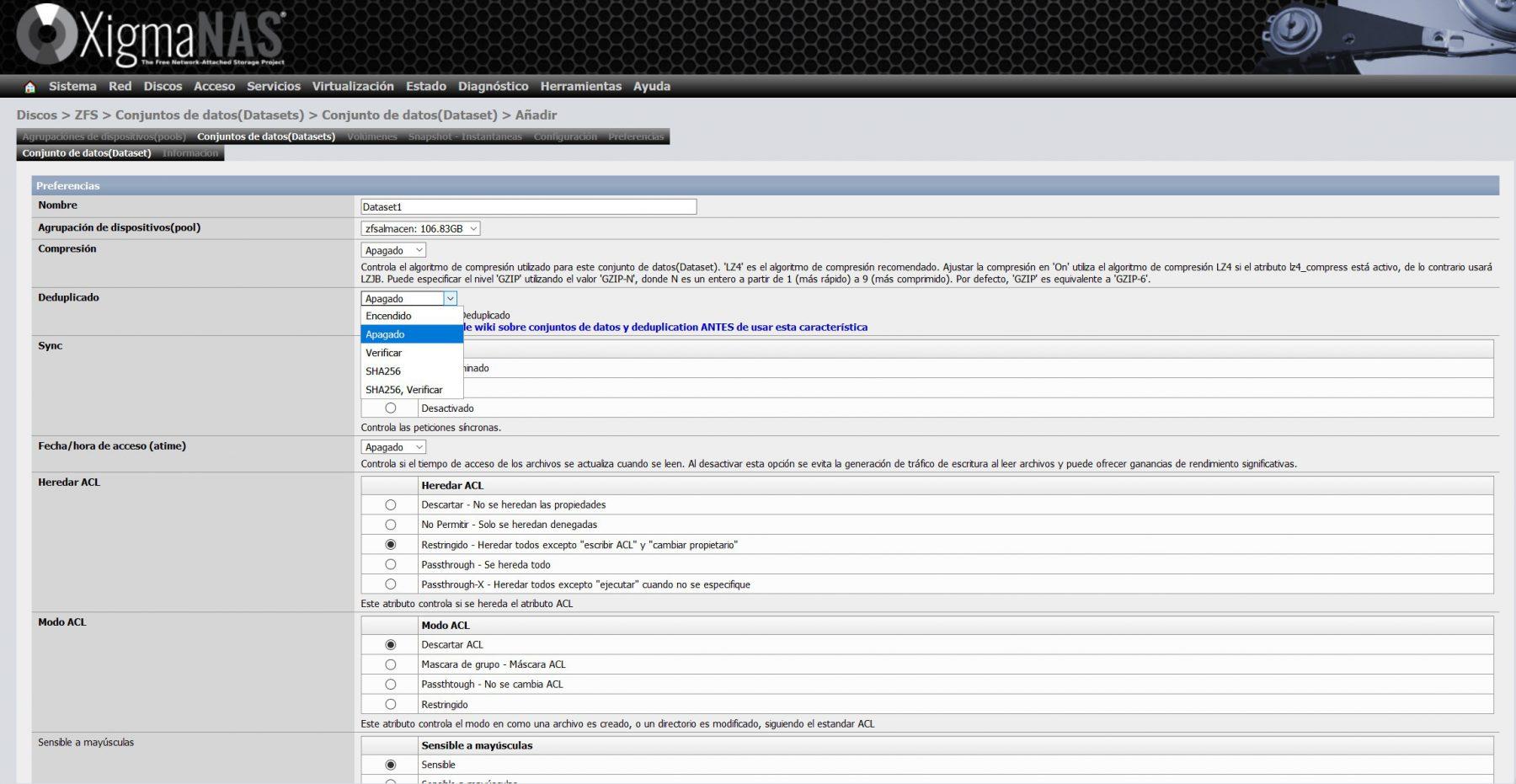
El resto de opciones de configuración disponibles son las siguientes:
Una vez creado el dataset, nos aparecerá de esta manera dentro del pool «zfsalmacen» que hemos creado anteriormente.

No debemos olvidar que también podremos crear dispositivos por bloques, los llamados volúmenes en ZFS:

Otras opciones de ZFS
Otras opciones disponibles son las instantáneas o snapshots, podremos crear millones de instantáneas, ya sean programadas o manualmente. Para configurar una instantánea, simplemente pinchamos en el «+» para añadir una nueva:
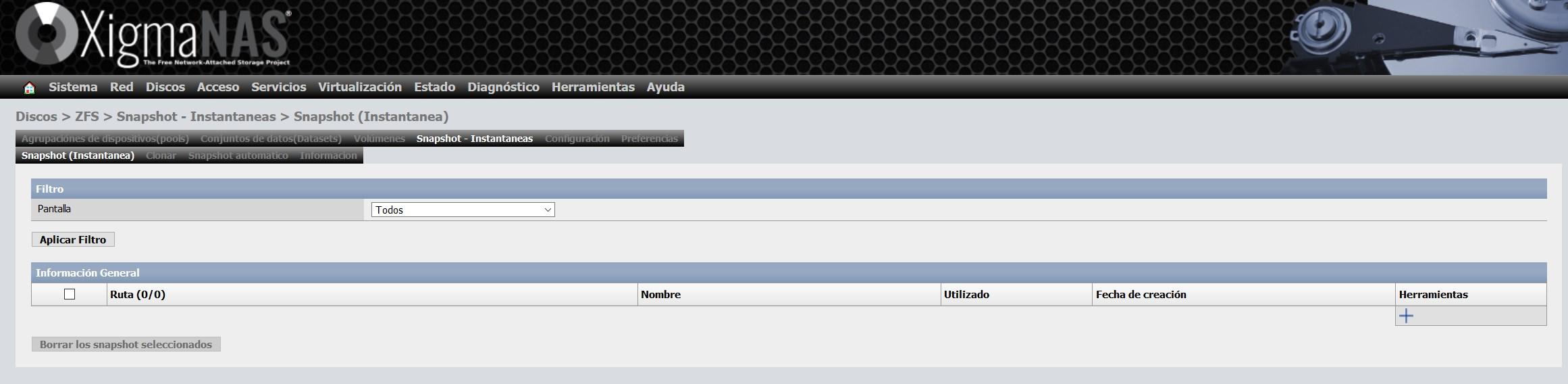
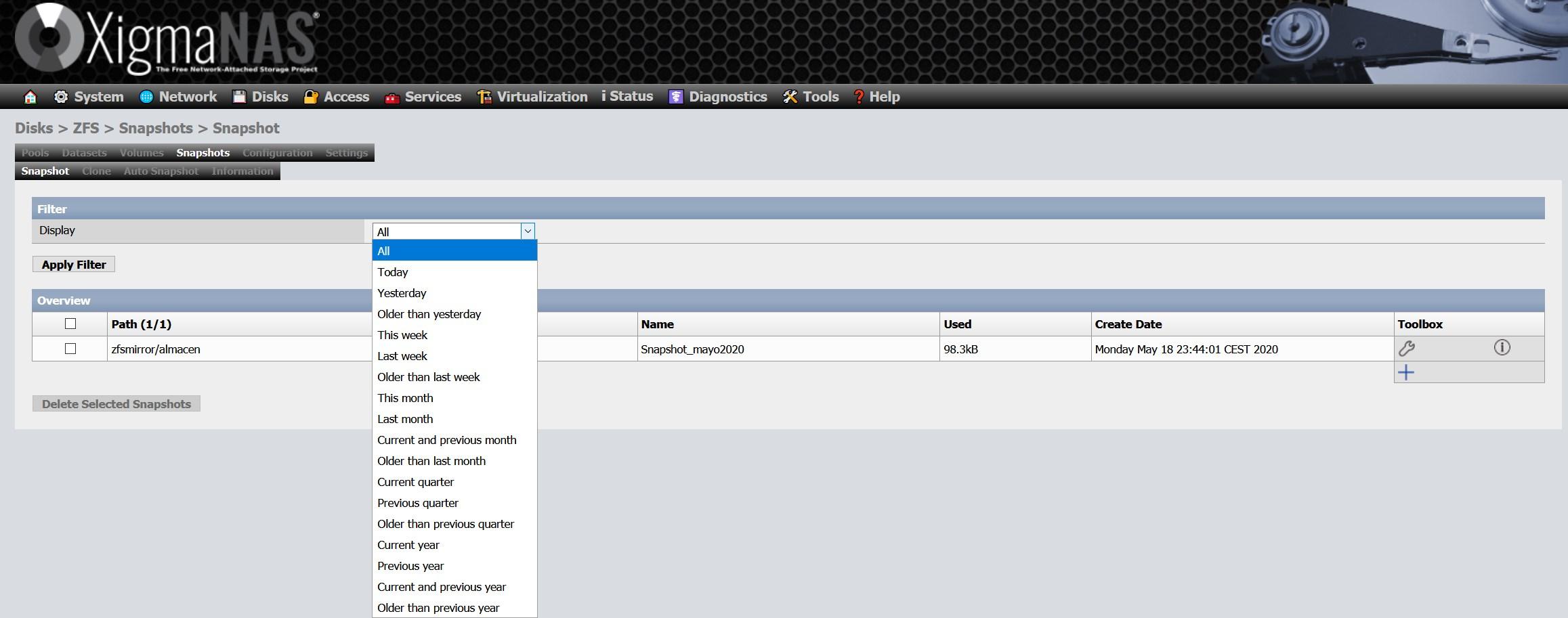
Seleccionamos a qué queremos realizar un snapshot, podremos hacerlo al pool completo, o solamente a uno o varios dataset que tenemos dentro del pool:
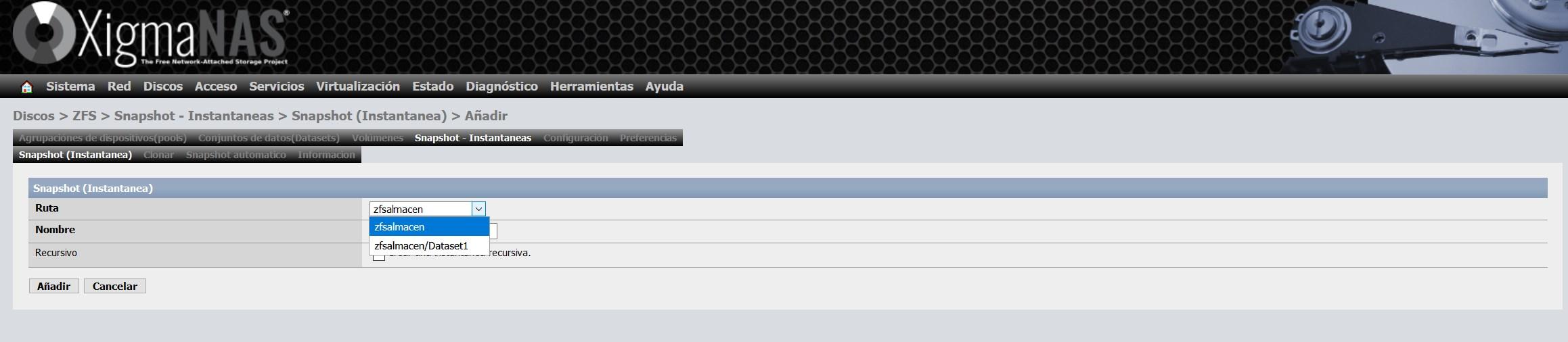
Una vez creada la instantánea, veremos algo como esto:
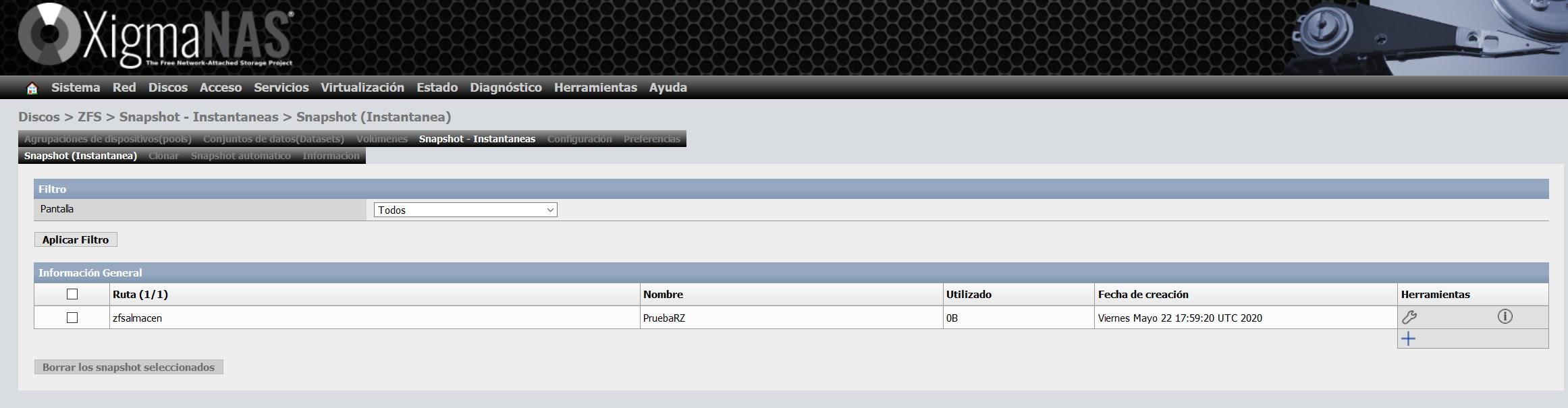
Lo más importante es la columna de «utilizado», ya que es el espacio que ocupa esa instantánea, y es debido a que se han realizado modificaciones o se han eliminado datos. Gracias a que los snapshots son nativos en ZFS, la eficiencia es realmente impresionante.
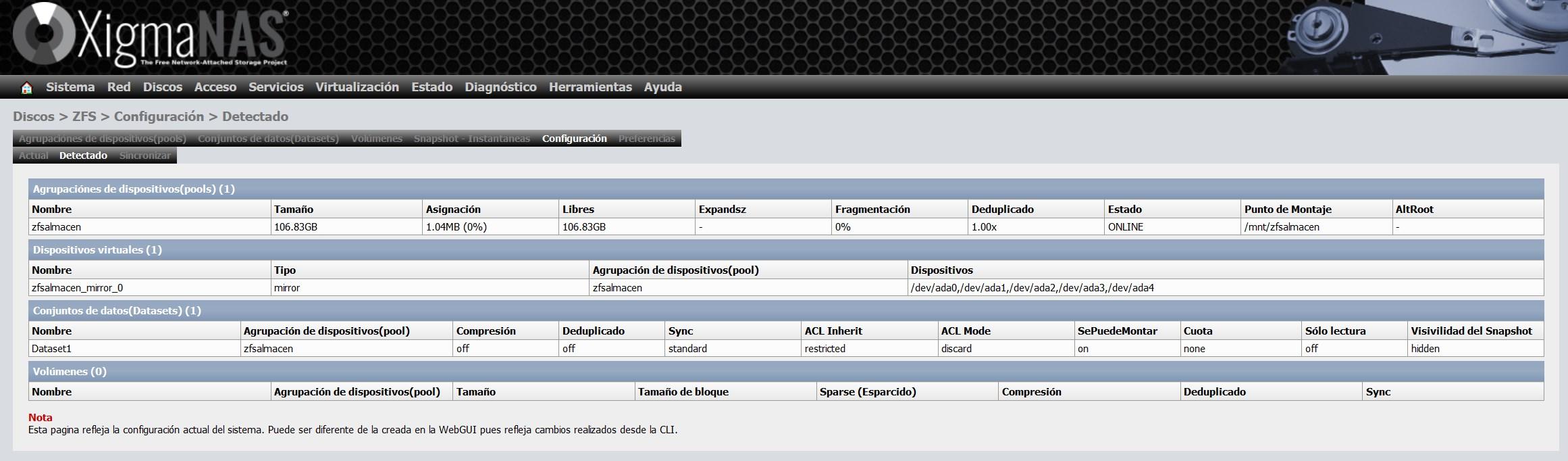
En la sección de «Configuración» tendremos un resumen de todo lo que hemos configurado hasta el momento, podremos ver los dispositivos virtuales, los pools, y también los dataset y volúmenes creados.
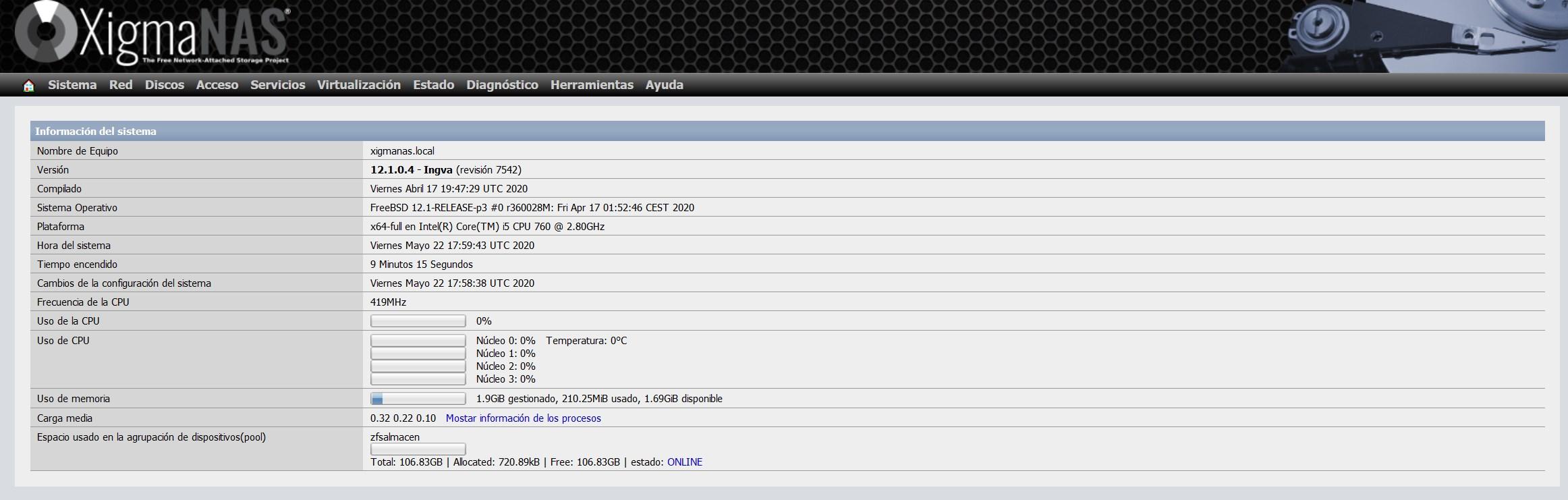
En el menú principal del sistema operativo, podremos ver que tenemos el pool «zfsalmacen», y nos indicará el espacio total, ocupado y disponible.
Tal y como habéis visto, ZFS es un sistema de archivos muy avanzados y nos permite una gran configurabilidad. En caso de fallo de un disco, basta con ponerlo fuera de línea, agregar uno nuevo, añadirlo al pool y realizar un scrub para que revise todo el pool y haga una regeneración de los datos.
Configuración y puesta en marcha de ZFS en Debian y otros
Aunque ZFS es un sistema de archivos avanzado, debido a algunos problemas con la licencia de uso, muchas distribuciones Linux no lo soportan por defecto, por lo que la puesta en marcha puede ser algo tediosa en muchos sistemas al tener que instalar y configurar el sistema de archivos manualmente.
Si queremos utilizar este sistema de archivos en nuestro sistema operativo, podemos descargarlo de forma totalmente gratuita desde su página web principal. Además, los principales repositorios cuentan también con paquetes precompilados, por lo que, por ejemplo, si queremos instalarlo en Ubuntu tan solo debemos descargarlo desde los repositorios oficiales con apt que, junto al resto de paquetes necesarios, se instalará de forma totalmente automática.
sudo apt install zfs
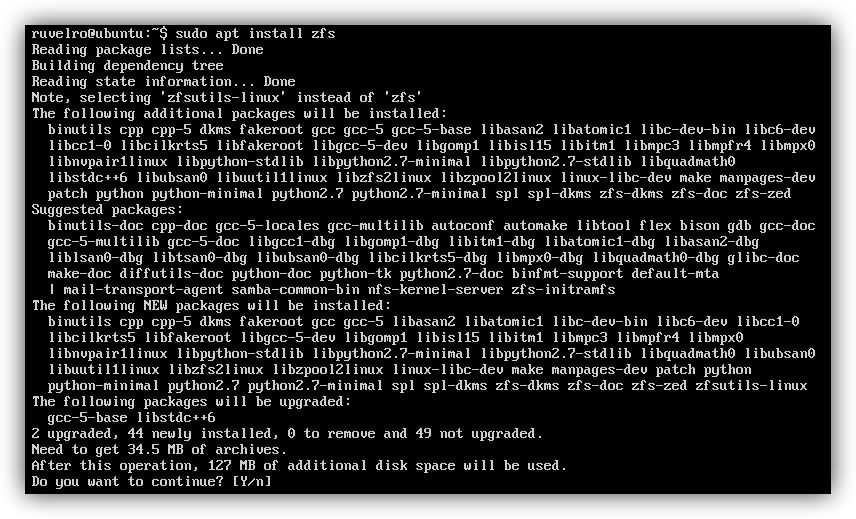
A la hora de gestionar los discos, este sistema de archivos utiliza el concepto de «pool«. Un pool de ZFS puede estar formado por uno o varios discos duros físicos. Por ejemplo, si tenemos 3 discos duros y queremos aprovechar su capacidad como una sola (stripe) con este sistema de archivos, tendremos que configurar un pool que incluya los 3 discos con el siguiente comando:
sudo zpool create pool-redeszone /dev/sdb /dev/sdc /dev/sdd
Si solamente tenemos un disco, simplemente pondremos un disco y tendremos un «stripe» de un solo disco.
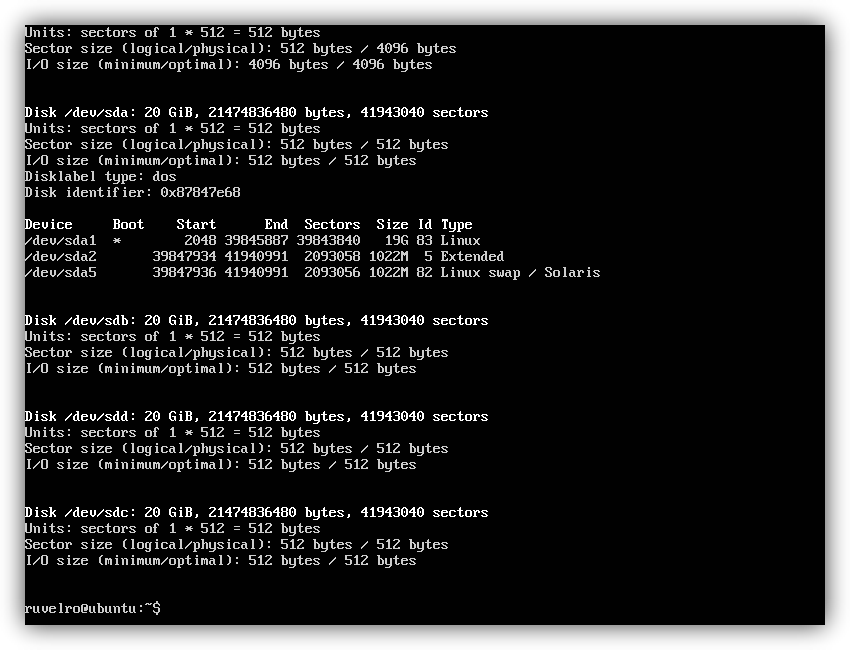
Podemos cambiar «pool-redeszone» por el nombre que queramos dar al pool. También debemos cambiar el «sdb», «sdc» y «sdd» que nosotros tengamos en nuestro sistema, por la correspondiente letra de cada disco que queramos añadir. Podemos ver todos los discos conectados con el comando:
sudo fdisk -l
 En caso de querer configurar un mirror con los mismos discos, debemos añadir el parámetro «mirror», quedando de la siguiente manera:
En caso de querer configurar un mirror con los mismos discos, debemos añadir el parámetro «mirror», quedando de la siguiente manera:
sudo zpool create pool-redeszone mirror /dev/sdb /dev/sdc /dev/sdd
Si queremos configurar un RAIDZ, sería así (se necesitan mínimo 3 discos):
sudo zpool create pool-redeszone raidz /dev/sdb /dev/sdc /dev/sdd
Si queremos configurar un RAIDZ2, sería así (se necesitan mínimo 4 discos):
sudo zpool create pool-redeszone raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
Si queremos configurar un RAIDZ3, sería así (se necesitan mínimo 5 discos):
sudo zpool create pool-redeszone raidz3 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
Por defecto, Linux montará el pool de discos en la raíz del sistema operativo /, por lo que, si queremos acceder a él y a sus datos, debemos situarnos sobre el directorio /pool-redeszone/.
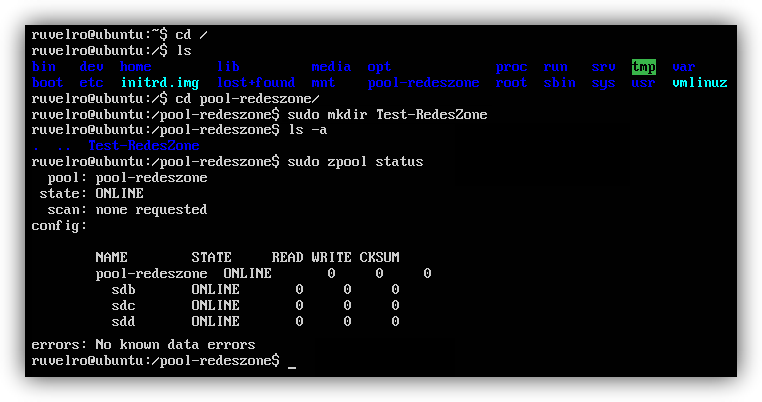
Si queremos conocer el estado de nuestro pool de discos, podemos hacerlo tecleando en el terminal:
sudo zpool status
 En caso de querer añadir discos al pool se hace con el comando:
En caso de querer añadir discos al pool se hace con el comando:
sudo zpool add pool-redeszone /dev/sdx
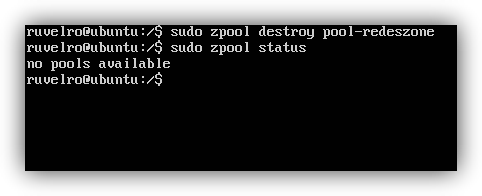
E incluso destruir el pool (con la correspondiente pérdida de todos los datos) con el comando:
sudo zpool destroy pool-redeszone
Otras opciones interesantes son los snapshots de ZFS, podremos crear un snapshot de esta forma:
zfs snapshot pool-redeszone/datos@2020-05-22
Y también podríamos borrar el snapshot creado de la siguiente forma:
zfs destroy pool-redeszone/datos@2020-05-22
Puntos fuertes y débiles de ZFS
Como hemos podido ver, ZFS nos facilita muchas opciones en la gestión de archivos, pero como todo en el mundo de la informática, tiene sus ventajas y sus desventajas. Vamos a ver algunas de ellas, las cuales pueden ser las más importantes o las que más nos pueden influir. De esta manera, podrás tener una idea más clara si es buena idea usar este sistema de archivos para tu servidor o no. Por lo que estos son los puntos fuertes y débiles de esta alternativa:
Ventajas
Ya conoces más a fondo qué es este sistema de archivos para servidores y cuáles son sus principales ventajas. Pero, de entre todas ellas, hay que tener en cuenta cuáles son las ventajas que puedes aprovechar al usar este el sistema ZFS. Por ello, aquí reunimos los principales puntos fuertes de este sistema:
- Se simplifica la administración: En este apartado es donde se unifica la gestión de volúmenes, RAID y sistemas de archivos. En todo caso, lo que vamos a necesitar son algunos comandos para poder crear nuevos volúmenes, niveles de redundancia, sistemas de compresión, puntos de montaje, sistemas de archivos y mucho más. También nos facilita la supervisión de todo esto.
- Garantiza la integridad de los datos: Cuando se realiza la escritura de los datos, se hace un cálculo que es una suma de comprobación, y esta se escribe junto a los mismos. Acto seguido, cuando se procede a leer estos datos, se realiza de nuevo ese cálculo a modo de verificación. Si este encuentra discrepancias, nos mostrará un error. Pero el propio sistema tratará de arreglarlo de forma automática.
- Copiado y pegado: En muchos sistemas de archivo, se sobreescriben datos, los antiguos se pierden, pero con ZFS esto no es así. Cuando se realiza esta acción, la nueva información se graba en un bloque diferente, de forma que no se pierden versiones anteriores. Lo que sí se actualizará son los metadatos de los sistemas de archivos. Esto permite que los archivos antiguos se conservan en caso de que queden bloqueados.
- Snapshots y clones: Permite crear instantáneas del sistema de archivos en un punto específico en el tiempo sin interrumpir el servicio, así como clonar un sistema de archivos a partir de un snapshot, lo cual es rápido y eficiente en términos de espacio.
- Ahorro de espacio: Reduce la necesidad de espacio de almacenamiento gracias a la compresión de datos y la eliminación de la duplicidad de los mismos.
Desventajas
Sin embargo, como todo, también cuenta con una serie de inconvenientes o, también, debilidades que te pueden interesar antes de apostar de lleno por esta opción. Por esto mismo, estas son las principales desventajas que presenta el uso del sistema de archivos ZFS para servidores:
- Rendimiento: Esto no suele ser un gran problema, siempre que no se cubra más de un 80% de su capacidad, pues pierde rendimiento. Esto se trata de un problema bastante común, pues cuando este pool se llena más de ese porcentaje, es necesario realizar una ampliación o hacer una migración a un almacenamiento mayor.
- No se puede reducir el pool: No es posible eliminar dispositivos o vdev una vez estos se han añadido.
- Capacidad limitada en la redundancia: Con una excepción de pasar de un pool a otro que sea una réplica, no es posible cambiar los tipos de redundancia. Si establecemos uno, la única posibilidad sería crear uno nuevo restaurando los datos desde una copia de seguridad u otra ubicación. Por lo cual se deja inservible el sistema anterior.
- Requisitos de memoria: ZFS utiliza mucha memoria RAM para caching y administración, siendo recomendado tener al menos 1 GB de RAM por cada 1 TB de almacenamiento, lo que puede ser un problema en muchos equipos.
- Compatibilidad y soporte: Originalmente diseñado para Solaris, aunque está disponible para Linux y otros sistemas menos conocidos, por lo que si creías que servía para cualquiera, estabas equivocado.
Como podemos ver, es un sistema de archivos avanzado para usuarios avanzados, pero una vez que te aprendes los comandos básicos y cómo funciona, es muy fácil su administración y mantenimiento. En caso de querer añadir un disco para caché o para LOG como os hemos explicado anteriormente, también se podría hacer, añadiendo «cache» y «log» seguido de los discos a elegir. Os recomendamos acceder a la web oficial de OpenZFS donde encontraréis una gran serie de recursos para instalar y utilizar este sistema de archivos tan avanzado.
Alternativas a ZFS
- Btrfs (B-tree File System): Similar a ZFS, Btrfs permite crear snapshots y clones de manera eficiente, una alternativa muy parecida aunque no tan madura como ZFS, al menos por ahora.
- EXT4 (Fourth Extended Filesystem): EXT4 es uno de los sistemas de archivos más utilizados y probados en Linux, y pese a que ZFS ahora también es compatible, como decíamos, en sus inicios no lo era.
- XFS: Si buscas un buen rendimiento con cargas y archivos grandes, puede ser la mejor alternativa de todas.
- APFS (Apple File System): Como su nombre indica, diseñado para equipos de Apple. Optimizado para discos de estado sólido. Si tienes un Mac, posiblemente te recomendaríamos este.
- NTFS (New Technology File System): Sistema de archivos estándar para Windows, ampliamente soportado. Si no usas Linux, y necesitas uno para Windows, este es el más popular y usado.
Estas son algunas de las alternativas más populares, aunque si necesitas otras, existen, con herramientas más específicas y diferentes a lo visto hoy.